Шифр группы – Количество студентов – Факультет – Куратор
Модели данных
Как отмечалось, инфологическая модель отображает реальный мир в некоторые понятные человеку концепции, полностью независимые от параметров среды хранения данных. Существует множество подходов к построению таких моделей: графовые модели, семантические сети, модель "сущность-связь" и т.д.]. Наиболее популярной из них оказалась модель "сущность-связь", которая будет рассмотрена.
Инфологическая модель должна быть отображена в машинно-ориентированную даталогическую модель, "понятную" СУБД. В процессе развития теории и практического использования баз данных, а также средств вычислительной техники создавались СУБД, поддерживающие различные даталогические модели.
Сначала стали использовать иерархические даталогические модели. Простота организации, наличие заранее заданных связей между сущностями, сходство с физическими моделями данных позволяли добиваться приемлемой производительности иерархических СУБД на медленных ЭВМ с весьма ограниченными объемами памяти. Но, если данные не имели древовидной структуры, то возникала масса сложностей при построении иерархической модели и желании добиться нужной производительности.
Сетевые модели также создавались для мало ресурсных ЭВМ. Это достаточно сложные структуры, состоящие из "наборов" – поименованных двухуровневых деревьев. "Наборы" соединяются с помощью "записей-связок", образуя цепочки и т.д. При разработке сетевых моделей было предложено множество "маленьких хитростей", позволяющих увеличить производительность СУБД, но существенно усложнивших предложенные модели. Прикладной программист должен знать массу терминов, изучить несколько внутренних языков СУБД, детально представлять логическую структуру базы данных для осуществления навигации среди различных экземпляров, наборов, записей и т.п. Один из разработчиков операционной системы UNIX сказал: "Сетевая база – это самый верный способ потерять данные".
Сложность практического использования иерархических и сетевых СУБД заставляла искать иные способы представления данных. В конце 60-х годов появились СУБД на основе инвертированных файлов, отличающиеся простотой организации и наличием весьма удобных языков манипулирования данными. Однако такие СУБД обладают рядом ограничений на количество файлов для хранения данных, количество связей между ними, длину записи и количество ее полей.
Иерархическая модель данных
Иерархическая модель данных основана на графовом представлении информации. Такая модель организует данные в виде древовидной структуры. Она является реализацией логических связей типа "целое-часть".
Графическим способом представления иерархической структуры является дерево. Дерево представляет собой иерархию элементов, называемых узлами. Под элементами понимают совокупность атрибутов, описывающих объекты.
В иерархической модели имеется "корневой узел" или "корень" дерева. Корень находится на самом верхнем уровне и не имеет узлов, стоящих выше него. У одного дерева может быть только один корень. Остальные узлы называются порожденными. Каждый порожденный узел имеет исходный, находящийся на более высоком уровне. В рассмотренном примере узел "Университет" является корнем. Для узла "Дневное отделение" узел "Университет" является исходным. Между исходным узлом и порожденными узлами существует отношение "Один - ко - многим" (1:N)

Каждый узел дерева содержит один или несколько атрибутов, описывающих объект в данном узле. Порожденные узлы могут добавляться как в горизонтальном, так и в вертикальном направлении. Доступ к порожденным узлам возможен только через исходный узел, т.е. существует только один путь доступа к каждому узлу.
Достоинством иерархической модели является ее простота. К недостаткам можно отнести сложность отображения связи "Многие - ко - многим" (N:M), сложность включения новой информации в базу данных и удаление устаревшей.
Сетевая модель данных
Представим связи (отношения) между объектами "Студенческий коллектив"/'Студенческая группа"/'Комната в общежитии"/'Студент":
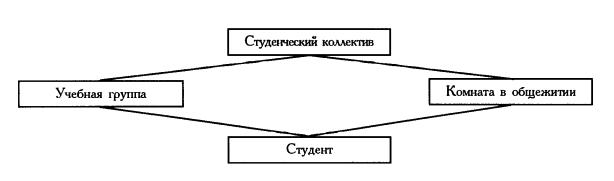
Из рисунка видно, что данная схема не является иерархической, т.к. порожденный элемент "Студент" имеет два исходных. Такие отношения между объектами, в которых порожденный элемент имеет более одного исходного, называются сетевыми структурами. Отличительная черта сетевой структуры от иерархической заключается в том, что любой элемент в сетевой структуре может быть связан с любым другим элементом.
В сетевых структурах существуют следующие виды взаимосвязей: "Один -ко- многим", "Многие - к- одному", что определяет простую сетевую структуру, и "Многие – ко - многим", что определяет сложную сетевую структуру.
Пример.
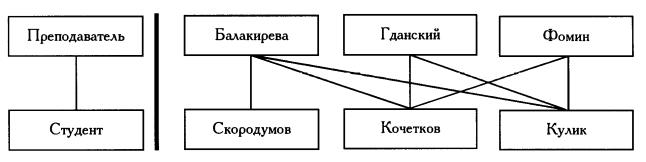
Здесь узел "Преподаватель" может иметь несколько порожденных узлов, т.к. преподаватель ведет занятия с несколькими студентами. Каждый студент обучается у нескольких преподавателей, узел "Студент" имеет более одного исходного.
База данных, описываемая сетевой моделью, состоит из нескольких наборов записей. Каждый тип набора представляет собой отношение между двумя или несколькими типами записей. Для каждого типа набора один тип записи может быть объявлен его владельцем и один или несколько других типов записей - членами набора. Каждый набор должен содержать один экземпляр записи, имеющий тип записи-владельца, и может содержать любое количество экземпляров каждого типа записей-членов набора.
Следует отличать понятия типа и экземпляра записи. "Студент" является типом записи, а строка символов "Петров Андрей" - экземпляром типа записи "Студент". В базе данных может храниться один или несколько экземпляров записи некоторого типа.
Аналогичное отношение существует и между типом набора и экземпляром. Например, тип набора "Состав группы", его экземпляр : "Петров Андрей, 1980 г. рожд., староста".
Определенный экземпляр типа записи-члена в экземпляре данного типа набора не может одновременно принадлежать более, чем одному экземпляру типа записи-владельца. В модели данных, представляющей взаимосвязь "Один -ко- многим", тип записи-владельца "владеет" от 0 до N экземплярами типа записи-члена. В свою очередь тип записи-члена в другом типе набора может играть роль типа записи-владельца. Запись-владелец данного набора может играть ту же роль в нескольких наборах.
Такая структура представляет собой иерархию. Следовательно, иерархическая модель данных является частным случаем сетевой модели.
Главное различие между сетевой и иерархической моделями данных состоит в том, что в сетевой модели каждая запись может участвовать в любом числе наборов. Кроме того, любая запись сетевой модели может играть роль, как владельца, так и члена набора. Основным недостатком сетевой модели является ее сложность.
Реляционная модель данных
Реляционная модель данных была предложена Э.Ф. Коддом как альтернатива сетевой и иерархической моделям данных, как модель данных, которая очень проста, позволяет достигнуть большей независимости данных и максимально гибка при ответе на случайные запросы пользователей.
Реляционная база данных есть набор двумерных таблиц, называемых в рамках модели отношениями. Каждый элемент таблицы есть элемент данных; все столбцы однородны, т.е. элементы данных, входящие в один столбец, имеют одну и туже природу. Множество элементов, входящих в один и тот же столбец таблицы, называется доменом, а имя столбца - именем атрибута. Каждое отношение есть множество строк, называемых кортежами, число элементов в кортеже совпадает с числом столбцов в таблице и называется степенью отношения.
В отношении не может быть двух одинаковых кортежей. Множество имен атрибутов с указанием подмножеств этого множества, относящихся к конкретным отношениям, называется схемой реляционной базы данных, а конкретный набор таблиц называется представителем, или экземпляром, реляционной базы данных.
Простота реляционной модели данных и возможность точной математической формулировки понятий, используемых в рамках этой модели, сделали эту модель наиболее удобной для теоретических разработок в области баз данных и очень популярной. В настоящее время она является наиболее полно разработанной моделью данных.
В реляционной базе данных каждая таблица должна иметь первичный ключ (ключевой элемент) - поле или комбинацию полей, которые единственным образом идентифицируют каждую строку в таблице. Благодаря своей простоте и естественности представления реляционная модель получила наибольшее распространение в СУБД для персональных компьютеров.
В основе реляционной модели лежит математическое понятие теоретико-множественного отношения.
Как уже говорилось выше, существует понятие "домена". Домен - это множество значений. Примером доменов могут служить множество целых чисел, множество названий городов, множество фамилий студентов и т.д.
Элементами отношения являются кортежи. Отношения представляются в виде двумерной таблицы, в которой строка есть кортеж. Каждый столбец соответствует только одной компоненте этого отношения. Такие таблицы обладают следующими свойствами:
Каждый элемент таблицы представляет собой один элемент данных, повторяющиеся группы отсутствуют;
Все столбцы в таблице однородные, т.е. элементы столбца имеют одинаковую природу;
В таблице нет двух одинаковых строк;
В операциях с такой таблицей ее строки и столбцы могут просматриваться в любом порядке и в любой последовательности безотносительно к их информационному содержанию и смыслу.
В реляционной модели данных объекты и взаимосвязи между ними представляются с помощью таблиц.
Таблицы являются основными структурными элементами системы управления реляционными базами данных. В Microsoft Access таблица является объектом, в котором данные сохраняются в формате записей (строк) и полей (столбцов). В отдельную таблицу обычно помещают однотипные данные, например, сведения о сотрудниках или заказах.
Например, таблица СТУДЕНТ представляет объект: студент с набором его атрибутов (свойств).
Реляционная база данных с логической точки зрения может быть представлена множеством двумерных таблиц самого различного предметного наполнения.
Столбцу (полю) таблицы можно присвоить имя и объявить его атрибутом. Список имен атрибутов одного отношения называется схемой отношения. Каждое отношение имеет свое имя. При этом порядок следования столбцов будет несущественным.
Столбец, значения которого однозначно идентифицируют каждую строку таблицы, называется ключом.
Пример
Рассмотрим отношение
Шифр группы – Количество студентов – Факультет – Куратор
Схема этого отношения имеет атрибуты:
1. Шифр группы, присвоим этому атрибуту имя A1,
2. Количество студентов, А2,
3. Факультет, А3,
4. Куратор, А4.
Этому отношению присвоим имя ГРУППА. Тогда схему отношения можно формально записать так:
Дата добавления: 2019-09-30; просмотров: 740;
Поиск по сайту
Узнать еще
- II.Группы маркетинга в зависимости от широты охвата рынка.
- III. Тесты для самоконтроля студентов
- А) преподавателя, б) студентов
- А. Все условные рефлексы подразделяют на те же группы, что и безусловные, на базе которых они были выработаны.
- Адаптация студентов к условиям вузовской жизни
- Адрес группы новостей
- Аккумуляторная батарея: назначение, тип батареи и его расшифровка. Параметры аккумуляторной батареи. Приборы контроля батареи.
- Алгоритм шифрования RSA

Публикации по технике и механике

Публикации по биологии

Публикации по информатике

Публикации по строительству

Публикации по физике

Публикации по химии

Публикации по электронике

Публикации по искусству

Публикации по истории
