Принципы помехоустойчивого кодирования
Идея помехоустойчивого кодирования состоит в том, что в передаваемую кодовую комбинацию по определенным правилам вносится избыточность (признаки разрешенной комбинации). Правила внесения избыточности, т.е. признаки, должны быть известны как на передающей, так и на приемной стороне. Если на приемной стороне эти признаки в кодовой комбинации не обнаруживаются, то считается, что кодовая комбинация принята правильно (является разрешенной). Внесение избыточности при использовании помехоустойчивых (корректирующих) кодов обязательно связано с увеличением числа разрядов (длины) кодовой комбинации — n. При этом все множество N0=2n комбинаций можно разбить на два подмножества: подмножество разрешенных комбинаций, т. е. обладающих определенными признаками, и подмножество запрещенных комбинаций, этими признаками не обладающих. Корректирующий код отличается от обычного тем, что в канал передаются не все кодовые комбинации (N0), которые можно сформировать из имеющегося числа разрядов n, а только их часть N, которая составляет подмножество разрешенных комбинаций: N< N0.
Если в результате искажений переданная кодовая комбинация переходит в подмножество запрещенных кодовых комбинаций, то ошибка будет обнаружена. Однако, если совокупность ошибок в данной кодовой комбинации превращает ее в какую-либо другую разрешенную, то в этом случае ошибки не могут быть обнаружены.
Поскольку любая из N разрешенных комбинаций может превратиться в любую из N0 возможных, то общее число таких случаев равно NN0. Очевидно, что число случаев, в которых ошибки обнаруживаются, равно N(N0 - N), где N0 - N — число запрещенных комбинаций. Тогда доля обнаруживаемых ошибочных комбинаций составит:
 (31.1)
(31.1)
Большинство разработанных до настоящего времени кодов предназначено для корректирования взаимно независимых ошибок определенной кратности и пачек (пакетов) ошибок.
Кратностью ошибки называется количество искаженных символов в кодовой комбинации.
Степень отличия любых двух кодовых комбинаций характеризуется кодовым расстоянием (расстоянием Хэмминга). Оно выражается числом символов, в которых комбинации отличаются одна от другой, и обозначается через d.
Чтобы получить кодовое расстояние между двумя комбинациями двоичного кода, достаточно подсчитать число единиц в сумме этих комбинаций по модулю 2.
Минимальное расстояние, взятое по всем параметрам кодовых разрешенных комбинаций кода, называют минимальным кодовым расстоянием.
Декодирование после приема может производиться таким образом, что принятая кодовая комбинация отождествляется с той разрешенной, которая находится от нее на наименьшем кодовом расстоянии. Такое декодирование называется декодированием по методу максимального правдоподобия.
Очевидно, что при минимальном кодовом расстоянии d = 1 все кодовые комбинации являются разрешенными.
При построении корректирующих кодов возникает задача нахождения наибольшего числа N кодовых комбинаций n-значного двоичного кода, расстояние между которыми не менее d. Общее решение этой задачи неизвестно. Некоторые частные результаты приведены в таблице 31.1:
Таблица 30.1
| d | N |
| 2n | |
| 2n-1 | |
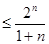
| |

| |
| … | … |
| 2j+1 | 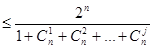
|
Одними из первых математически обоснованных и практически использованных корректирующих кодов были коды Хемминга. Коды Хемминга, представляющие собой просто совокупность перекрестных проверок на четность/нечетность, являются одной из разновидностей более широкого семейства корректирующих кодов — циклических кодов.
Циклические коды
Основные свойства и само название циклических кодов связаны с тем, что все разрешенные комбинации двоичных символов в передаваемом сообщении могут быть получены путем операции циклического сдвига некоторого исходного слова:
(a0 a1 a2 … an-2 an-1)
(an-1 a0 a1 … an-3 an-2)
(an-2 an-1 a0 … an-4 an-3)
Обычно кодовые комбинации циклического кода рассматривают не в виде последовательности нолей и единиц, а в виде полинома некоторой степени. Любое число в любой позиционной системе счисления можно представить в общем виде как:
F(x)=an-1xn-1 +an-2xn-2 +…+ a1x + a0 ,
где х — основание системы счисления;
ai — цифры данной системы счисления;
n-1, n-2, ... — показатель степени, в которую возводится основание, и одновременно порядковые номера, которые занимают разряды.
Идея построения циклического кода сводится к тому, что полином, представляющий информационную часть кодовой комбинации, нужно преобразовать в полином степени не более n-1, который без остатка делится на образующий полином Р(х). Существенно при этом, что степень последнего соответствует числу разрядов проверочной части кодовой комбинации. В циклических кодах все разрешенные комбинации, представленные в виде полиномов, обладают одним признаком: делимостью без остатка на образующий полином Р(х). Построение разрешенной кодовой комбинации сводится к следующему:
- представляем информационную часть кодовой комбинации длиной k в виде полинома Q(x);
- умножаем Q(x) на одночлен хr и получаем Q(x)xr, т. е. производим сдвиг k-разрядной кодовой комбинации на r разрядов;
- делим многочлен Q(x)xr на образующий полином Р(х), степень которого равна r.
Обнаружение ошибок при циклическом кодировании сводится к делению принятой кодовой комбинации на тот же образующий полином, который использовался при кодировании (его вид должен быть известен на приеме). Если ошибок в принятой кодовой комбинации нет (или они такие, что данную передаваемую кодовую комбинацию превращают в другую разрешенную), то деление на образующий полином будет выполнено без остатка. Если при делении получится остаток, то это и свидетельствует о наличии ошибки.
Сжатие информации
В общем случае под сжатием данных понимают процесс преобразования большого объема данных в меньший объем. Существует большое количество методов сжатия. Для оценки их эффективности используют показатель — степень сжатия, определяющий отношение объема несжатых данных к объему сжатых.
Алгоритмы сжатия подразделяют на две категории: симметричные и асимметричные. Метод симметричного сжатия основан примерно на тех же алгоритмах и позволяет выполнять почти такой же объем работы, что и распаковка. В программах обмена данными, использующих сжатие и распаковку, обычно для большей эффективности применяют именно симметричные алгоритмы.
При асимметричном сжатии в одном направлении выполняется значительно больший объем работы, чем в другом. Обычно на сжатие затрачивается намного больше времени и системных ресурсов, чем на распаковку. Так, при создании базы данных изображений графические данные сжимаются для хранения всего однажды, зато распаковываться с целью отображения данные могут неоднократно. В этом случае большие затраты времени на сжатие, чем на распаковку, вполне оправданы и такой алгоритм, можно считать эффективным.
Алгоритмы, асимметричные «в обратном направлении» (т. е. когда на сжатие затрачивается меньше времени, чем на распаковку), применяются значительно реже. В частности, при резервном копировании информации, когда большинство скопированных файлов никогда не будет прочитано, уместен алгоритм, выполняющий сжатие значительно быстрее, чем распаковку.
Широко распространены методы сжатия данных, базирующиеся на словарях (когда для кодировки входных данных используются специальные словари). Среди данных методов выделяют адаптивные, полуадаптивные и неадаптивные.
Алгоритмы сжатия, спроектированные специально для обработки данных только определенных типов, называют неадаптивными. Такие неадаптивные кодировщики содержат статический словарь предопределенных подстрок, о которых известно, что они появляются в кодируемых данных достаточно часто. Адаптивные кодировщики не зависят от типа обрабатываемых данных, поскольку строят свои словари полностью из поступивших (рабочих) данных. Они не имеют предопределенного списка статических подстрок, а, наоборот, строят фразы динамически, в процессе кодирования. Адаптивные компрессоры настраиваются на любой тип вводимых данных, добиваясь в результате максимально возможной степени сжатия, в отличие от неадаптивных компрессоров, которые позволяют эффективно закодировать только входные данные строго определенного типа, для которого они были разработаны.
Метод полуадаптивного кодирования основан на применении обоих словарных методов кодирования. Полуадаптивный кодировщик работает в два прохода. При первом проходе он просматривает все данные и строит свой словарь, при втором — выполняет кодирование. Этот метод позволяет построить оптимальный словарь, прежде чем приступать к кодированию.
Наряду с методами сжатия, не уменьшающими количество информации в сообщении, применяются методы сжатия, основанные на потере малосущественной информации.
Среди простых алгоритмов сжатия наиболее известен алгоритм RLE (Run Length Encoding), позволяющий сжимать данные любых типов. Этот алгоритм сжатия основан на замене цепочки из одинаковых символов символом и значением длины цепочки. Например, символьная группа из восьми символов АААААААА, занимающая восемь байт, после RLE-кодирования будет представлена всего двумя символами 8А и будет занимать, соответственно, два байта. При этом будет обеспечена степень сжатия 4:1. Данный метод эффективен при сжатии растровых изображений, но малополезен при кодировании текста.
При передаче информации широко используются и методы разностного кодирования — предсказывающие (предиктивные) методы.
При методе разностного кодирования разности амплитуд отсчетов представляются меньшим числом разрядов, чем сами амплитуды. Разностное кодирование реализовано в методах дельта-модуляции и ее разновидностях. Предсказывающие (предиктивные) методы основаны на экстраполяции значений амплитуд отсчетов.
Методы MPEG (Moving Pictures Experts Group) используют предсказывающее кодирование изображений (для сжатия данных о движущихся объектах вместе со звуком). Так, если передавать только изменившиеся во времени пиксели изображения, то достигается сжатие в несколько десятков раз. Данные методы становятся стандартами для цифрового телевидения.
Для сжатия данных об изображениях используют методы типа JPEG (Joint Photographic Expert Group), основанные на потере малосущественной информации (не различимые для глаза оттенки кодируются одинаково, коды могут стать короче). В этих методах сжимаемая последовательность пикселей делится на блоки, в каждом блоке производится преобразование Фурье и устраняются высокие частоты. Изображение восстанавливается по коэффициентам разложения для оставшихся частот.
Другой принцип воплощен во фрактальном кодировании, при котором изображение, представленное совокупностью линий, описывается уравнениями этих линий.
Широко известный метод Хаффмена относится к статистическим методам сжатия. Идея метода — часто повторяющиеся символы нужно кодировать более короткими цепочками битов, чем цепочки редких символов. Строится двоичное дерево, листья соответствуют кодируемым символам, код символа представляется последовательностью значений ребер (эти значения в двоичном дереве суть 1 и 0), ведущих от корня к листу. Листья символов с высокой вероятностью появления находятся ближе к корню, чем листья маловероятных символов.
Распознавание кода, сжатого по методу Хаффмена, выполняется по алгоритму, аналогичному алгоритмам восходящего грамматического разбора.
Кодирование по алгоритму Хаффмена широко используется для факсимильной передачи изображений по телефонным каналам и сетям передачи данных. Этот алгоритм не является адаптивным. В нем, как правило, применяется фиксированная таблица кодовых значений, которые выбираются специально для представления документов, подлежащих факсимильной передаче.
Кроме упомянутых методов сжатия, широкое распространение получили адаптивные методы сжатия без потерь, основанные на алгоритме LZ (Лемпеля-Зива). В частности, метод сжатия на основе LZ применен в модемном протоколе V.42bis.
В LZ-алгоритме используется следующая идея: если в тексте сообщения появляется последовательность из двух ранее уже встречавшихся символов, то эта последовательность объявляется новым символом, для нее назначается код, который при определенных условиях может быть значительно короче исходной последовательности. В дальнейшем в сжатом сообщении вместо исходной последовательности записывается назначенный код. При декодировании повторяются аналогичные действия и поэтому становятся известными последовательности символов для каждого кода.
Так, в модемном протоколе V.42bis заменяет конкретные, наиболее часто встречающиеся последовательности символов (строк) на более короткие кодовые слова. Алгоритм использует словарь для сохранения наиболее часто встречающихся строк вместе с кодовыми словами, которые их представляют. Словарь строится и модифицируется динамически. Размер словаря может быть различным, стандартизировано только минимальное значение — 512 элементов (строк). Конкретное значение выбирается обоими модемами при установлении соединения. Кроме того, согласовывается максимальная длина строки, которая может быть сохранена в словаре, в диапазоне от шести до 250 символов.
Словарь может быть представлен как набор (лес) деревьев, в котором корню каждого дерева соответствует символ алфавита и, наоборот, каждому символу соответствует дерево в словаре. Каждое дерево представляет набор известных (уже встретившихся) строк, начинающихся с символа, соответствующего корню. Каждый узел дерева соответствует набору строк в словаре. И, наконец, каждый листьевой узел соответствует одной известной строке.
В самом начале каждое дерево в словаре состоит только из корневого узла, которому присвоено уникальное кодовое слово. При поступлении нового символа выполняется процедура отождествления накопленной (отождествленной) к предыдущему шагу строки и текущего символа. Фактически эта процедура сводится к поиску строки, дополненной текущим символом, в словаре. Эта процедура начинается с единственного символа и в этом случае всегда завершается успешно, так как в словаре всегда есть односимвольные строки, соответствующие каждому символу алфавита. Если отождествленная на предыдущем шаге строка плюс символ соответствует элементу словаря (найдена в нем), и этот элемент не был создан при предыдущем выполнении процедуры отождествления строки, строка дополняется текущим символом и будет использована при следующем вызове процедуры отождествления. Процесс продолжается до тех пор, пока:
- строка не достигает максимально возможной длины (согласованной модемами при установлении соединения);
- либо дополненная строка не найдена в словаре;
- либо она была найдена, но этот элемент был создан при предыдущем вызове. В этом случае присоединенный к строке символ удаляется из нее и называется «неотождествленным», строка кодируется кодовым словом, и на следующем шаге будет состоять только из неотождествленного символа.
Во время процесса сжатия словарь динамически дополняется новыми элементами (строками), которые соответствуют подстрокам, встречающимся в потоке данных. Новые строки образуются добавлением неотождествленного символа к существующей строке, и это означает создание нового узла дерева.
Словари должны быть модифицированы в обоих модемах — передающем и принимающем. При этом передатчик всегда находится на один шаг (на одну строку) впереди приемника в цикле модификации словаря. Таким образом, в принимающем модеме первый символ принятого кодового слова (который будет равен D) должен быть использован для модификации словаря приемника. Приемник V.42bis всегда полагает, что первый символ каждой строки (соответствующей принятому кодовому слову) должен быть использован для дополнения предыдущей строки и создания нового элемента словаря.
Наиболее важными особенностями алгоритма, реализованного в протоколе V.42bis являются следующие:
- если в потоке данных часто встречаются те подстроки, которые уже есть в словаре, то новые элементы словаря создаются редко и словарь переполняется медленно;
- для представления максимального номера элемента (строки) словаря требуется 9 бит для словаря в 512 элементов, 10 — для словарей, содержащих до 1024 элементов, 11 — до 2048 элементов и т. д. Однако не все номера должны быть представлены максимальным количеством бит, и этот механизм означает, что размер кодового слова увеличивается с 9 до максимального значения по мере заполнения словаря. Это уменьшает объем данных на первоначальных этапах;
- если на вход передатчика поступает хорошо перемешанный (в статистическом смысле) поток символов, то высока вероятность, что каждый следующий символ будет «неотождествленным» (такая же ситуация существует сразу после инициализации словаря — он еще пуст). Для этого случая предназначен прозрачный режим работы передатчика, т. е. режим без сжатия, когда передача кодовых слов не осуществляется, а каждый приходящий на вход передатчика символ транслируется в линию и далее в приемник.
Дата добавления: 2021-03-18; просмотров: 717;
Поиск по сайту
Узнать еще
- III. Части речи и принципы их классификации
- IV. Критерии и принципы обеспечения безопасности
- IV. Основные принципы этикета государственного служащего
- VIII. Принципы развивающего обучения.
- А.7 Устройство и принципы действия адсорбционных аппаратов
- Активные маскирующие помехи и принципы защиты от них
- Алгоритмы эффективного кодирования неравновероятных взаимнонезависимых символов источников сообщений
- Аллергия. Типы аллергических реакций и принципы их терапии

Публикации по технике и механике

Публикации по биологии

Публикации по информатике

Публикации по строительству

Публикации по физике

Публикации по химии

Публикации по электронике

Публикации по искусству

Публикации по географии

Публикации по медицине
