Современные технологии баз и банков данных
К современным технологиям обработки данных относится:
распределенная обработка;
системы Клиент-Сервер;
интегрированные (федеративные) системы;
мультибазы данных;
объектно-ориентированные базы данных.
Распределенная обработка предполагает, что определенная задача, обрабатывающая данные может быть распределена на нескольких участках сети. Необходимо понимать разницу между распределенной и параллельной обработкой. При параллельной обработке характерно когда машины с физической точки зрения расположены близко друг к другу. А при распределенной обработке это совсем необязательно и зачастую бывает, что машины удалены на значительные расстояния. Связь между машинами осуществляется с помощью сети и специального программного обеспечения управления сетью (СЛАЙД 9).
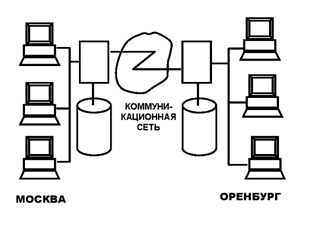
Чаще всего бывает, что узлы при распределенной обработке распределены физически, а также географически, хотя в действительности достаточно, чтобы они были распределены логически.
Необходимость распределенной обработки объясняется тем, что крупные предприятия как правило имеют распределенную структуру, по крайней мере они распределены логически (по видам деятельности: на бухгалтерию, склад и т.д.) и физически (на отделы, группы, лаборатории и т.д.). Из этого следует, что данные в них также распределены, поскольку на каждом уровне ведется работа с данными, относятся к этому уровню. Таким образом, в распределенной системе можно отобразить структуру предприятия с помощью соответствующей структуры БД, т.е. данные локального значения могут храниться локально, что в наибольшей мере отвечает логической структуре системы, тогда как доступ к удаленным данным осуществляется по мере необходимости.
Системы типа «Клиент-Сервер» могут рассматриваться как особый случай распределенной обработки. Точнее, система К-С сама является распределенной, в которой одни узлы являются клиентами, а другие серверами. Все данные хранятся на серверах, все приложения исполняются клиентами, а места их соединения скрыты от пользователя (СЛАЙД 10, 11).
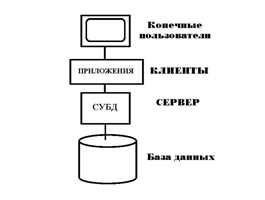
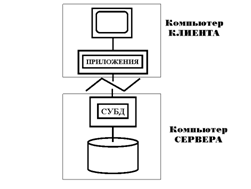
Интегрированные (федеративные) системы и мультибазы данных.
Направление интегрированных или федеративных систем неоднородных БД и мульти-БД появилось в связи с необходимостью комплексирования систем БД, основанных на разных моделях данных и управляемых разными СУБД.
Основной задачей интеграции неоднородных БД является предоставление пользователям интегрированной системы глобальной схемы БД, представленной в некоторой модели данных, и автоматическое преобразование операторов манипулирования БД глобального уровня в операторы, понятные соответствующим локальным СУБД. В теоретическом плане проблемы преобразования решены, имеются реализации.
При строгой интеграции неоднородных БД локальные системы БД утрачивают свою автономность. После включения локальной БД в федеративную систему все дальнейшие действия с ней, включая администрирование, должны вестись на глобальном уровне. Поскольку пользователи часто не соглашаются утрачивать локальную автономность, желая тем не менее иметь возможность работать со всеми локальными СУБД на одном языке и формулировать запросы с одновременным указанием разных локальных БД, развивается направление мульти-БД. В системах мульти-БД не поддерживается глобальная схема интегрированной БД и применяются специальные способы именования для доступа к объектам локальных БД. Как правило, в таких системах на глобальном уровне допускается только выборка данных. Это позволяет сохранить автономность локальных БД.
Как правило, интегрировать приходится неоднородные БД, распределенные в вычислительной сети. Это в значительной степени усложняет реализацию. Дополнительно к собственным проблемам интеграции приходится решать все проблемы, присущие распределенным СУБД: управление глобальными транзакциями, сетевую оптимизацию запросов и т.д. Очень трудно добиться эффективности.
Как правило, для внешнего представления интегрированных и мульти-БД используется (иногда расширенная) реляционная модель данных. В последнее время все чаще предлагается использовать объектно-ориентированные модели, но на практике пока основой является реляционная модель. Поэтому, в частности, включение в интегрированную систему локальной реляционной СУБД существенно проще и эффективнее, чем включение СУБД, основанной на другой модели данных.
Объектно-ориентированные базы данных.
Направление объектно-ориентированных баз данных (ООБД) возникло сравнительно давно (середине 1980-х). Возникновение направления ООБД определяется прежде всего потребностями практики: необходимостью разработки сложных информационных прикладных систем, для которых технология предшествующих систем БД не была вполне удовлетворительной.
В наиболее общей и классической постановке объектно-ориентированный подход базируется на следующих концепциях:
· объекта и идентификатора объекта;
· атрибутов и методов;
· классов;
· иерархии и наследования классов.
Любая сущность реального мира в объектно-ориентированных языках и системах моделируется в виде объекта. Любой объект при своем создании получает генерируемый системой уникальный идентификатор, который связан с объектом все время его существования и не меняется при изменении состояния объекта.
Каждый объект имеет состояние и поведение. Состояние объекта - набор значений его атрибутов. Поведение объекта - набор методов (программный код), оперирующих над состоянием объекта. Значение атрибута объекта - это тоже некоторый объект или множество объектов. Состояние и поведение объекта инкапсулированы в объекте; взаимодействие объектов производится на основе передачи сообщений и выполнении соответствующих методов.
Наиболее важным новым качеством ООБД, которого позволяет достичь объектно-ориентированный подход, является поведенческий аспект объектов. В прикладных информационных системах, основанных на БД с традиционной организации (вплоть до тех, которые базировались на семантических моделях данных), существовал принципиальный разрыв между структурной и поведенческой частями. Структурная часть системы поддерживалась всем аппаратом БД, ее можно было моделировать, верифицировать и т.д., а поведенческая часть создавалась изолированно. В частности, отсутствовали формальный аппарат и системная поддержка совместного моделирования и гарантирования согласованности этих структурной (статической) и поведенческой (динамической) частей. В среде ООБД проектирование, разработка и сопровождение прикладной системы становится процессом, в котором интегрируются структурный и поведенческий аспекты. Конечно, для этого нужны специальные языки, позволяющие определять объекты и создавать на их основе прикладную систему.
2. Управление информационными ресурсами в АИС
Стремительный рост популярности SQL является одной из самых важных тенденций в современной компьютерной промышленности. Сегодня SQL поддерживает более ста СУБД, работающих как на мэйнфреймах, так и на ПК. SQL единственный стандартный язык БД. Был принят, а затем дважды дополнен официальный стандарт на SQL.
SQL является инструментом, предназначенным для выборки и обработки информации, содержащейся в компьютерной БД. SQLявляется языком программирования, который применяется для организации взаимодействия пользователя с БД. SQL работает только с реляционными БД.
Следующая схема иллюстрирует работу SQL при доступе к БД (СЛАЙД 12).
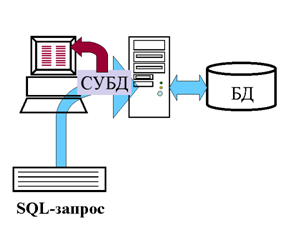
В вычислительной системе имеется БД, в которой хранится информация. В компьютерной системе устанавливается специальная программа, называемая СУБД. Если пользователю необходимо получить информацию из БД, он запрашивает ее у СУБД с помощью SQL. СУБД обрабатывает запрос, находит требуемые данные и посылает их пользователю. Этот процесс носит название «запрос к БД».
SQL используется для реализации всех функциональных возможностей, которые СУБД предоставляет пользователю. К ним относятся:
· организация данных. SQL позволяет изменять структуру представления данных, а также устанавливать отношения между элементами БД;
· выборка данных. SQL позволяет извлекать информацию из БД;
· обработка данных. SQL позволяет изменять БД, т.е. добавлять в нее новые данные, а также удалять или обновлять уже имеющиеся в ней данные;
· управление доступом;
· совместное использование данных. SQL координирует совместное использование данных пользователями, чтобы они не мешали друг другу;
· целостность данных. SQL обеспечивает защиту БД от разрушения из-за несогласованных изменений или отказе системы.
SQL представляет собой неотъемлемую часть СУБД, инструмент, с помощью которого осуществляется связь с пользователя с ней. Следующая схема показывает структуру типичной СУБД. Компоненты которой соединяются в единое целое с помощью SQL (СЛАЙД 13).
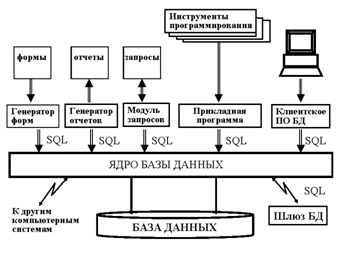
Шлюз БД представляет собой программу, которая позволяет СУБД одного типа связываться с СУБД другого типа.
SQL стандартизован Американским национальным институтом стандартов (ANSI) и Международной организацией по стандартизации (ISO) в 1989 г. – SQL 1, 1992 – SQL 2.
В технологии БД существует важная область, которую не затрагивают официальные стандарты. Это способность к взаимодействию с другими БД – методы, с помощью которых различные БД могут обмениваться информацией. В Windows эта функция реализуется с помощью протокола ODBC (открытый доступ к базам данных). ODBC является стандартом межплатформенного доступа к БД, поддерживаемыми всеми ведущими СУБД.
Рост популярности компьютерных сетей оказал большое влияние на управление БД и придал SQL новые возможности. По мере распространения сетей приложения, которые раньше работали на центральном мини-компьютере или мэейнфрейме, переводятся на серверы и рабочие станции ЛВС. В таких сетях SQL связывает приложения, выполняющиеся на рабочей станции, и СУБД, управляющую совместно используемыми данными на сервере. С появлением трехуровневой архитектуры Internet язык SQL стал связующим звеном между управляющим приложением (второй уровень – сервер приложений или Web-сервер) и сервером БД (третий уровень).
Централизованная архитектура (СЛАЙД 14).
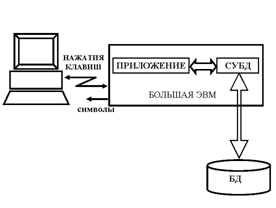
Использовалась в первоначальных СУБД для мини-компьютеров. При подобной архитектуре и СУБД, и сами данные размещаются на центральном мини-компьютере или мэйнфрейме вместе с приложением, принимающим входную информацию с пользовательского терминала и отражающим на нем же данные. Характерным является то, что при увеличении числа пользователей возрастает нагрузка на систему.
Архитектура файл/сервер (СЛАЙД 15).
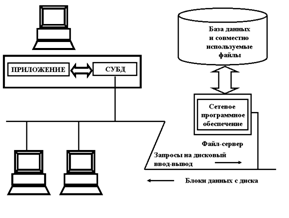
При такой архитектуре приложение, выполняемое на ПК, может получить «прозрачный» доступ к файловому серверу, на котором хранятся совместно используемые файлы. Когда приложению, работающему на ПК, требуется получить данные из такого файла, сетевое программное обеспечение автоматически считывает требуемый блок данных с сервера. Эта архитектура поддерживалась первыми версиями СУБД. При выполнении обычных запросов она обеспечивала приемлемую производительность. Однако, при последовательном просмотре БД, СУБД постоянно запрашивает новые записи из БД, которая физически расположена на сервере. В этом случае сильно возрастает нагрузка на сеть, что приводит к снижению производительности системы в целом.
Архитектура клиент-сервер (рассматривалась ранее, во 2-м вопросе).
Трехуровневая архитектура Internet (СЛАЙД 16).
В начале своего развития WWW являлась средой просмотра статических документов и развивалась независимо от рынка СУБД. Однако, по мере развития оказалось, что это очень удобный способ доступа к корпоративным БД.
Методы связывания Web-серверов и СУБД в ходе своего развития вылились в трехуровневую архитектуру.
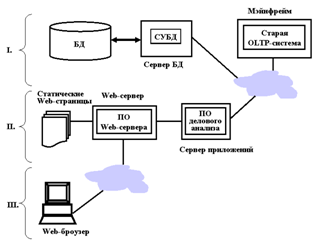
I. – информационный уровень
II. – прикладной уровень
III. – клиентский уровень
OLTP – оперативная
обработка транзакций
Интерфейсом пользователя является Web-броузер, выполняющийся на ПК. Броузер взаимодействует с Web-сервером, уровень которого можно оценить как прикладной. Если пользователь запрашивает нечто большее чем просто Web-страницы, Web-сервер адресует запрос серверу приложений, чья роль заключается в анализе запроса. Запрос может включать обращение к унаследованной системе, выполняющейся на мэйнфрейме (OLTP-системе), либо к корпоративной БД. Это уже информационный уровень. В этой архитектуре SQL закрепился как стандартное средство взаимодействия между вторым и третьим уровнями.
Хранилище данных.
В настоящее время реляционные БД заняли абсолютно доминирующую позиция на рынке БД. До тех пор, пока такая БД используется в пределах малой или средней корпорации проблем не возникает. Однако, даже для них при возникновении запроса, связанного с принятием решения (например, нахождение средней стоимости заказа, или поиск прироста продаж за определенный период времени), могут требовать сканирования огромных таблиц и выполняться минутами или даже часами. Если выполнять подобные операции в период пика деловых транзакций, это может вызвать серьезное снижение производительности всей системы. Еще одну проблему составляет размещение данных, необходимых для получения ответов на вопросы из области делового анализа: они могут быть распределены между многими БД, причем, как правило, еще и поддерживаемыми разними СУБД и на разных компьютерных платформах.
Необходимость в полноценном использовании информационного потенциала предприятия, т.е. накопленных данных, а также практические проблемы, связанные с производительностью, породили новое техническое решение, получившее название «хранилище данных» (СДАЙД 17).
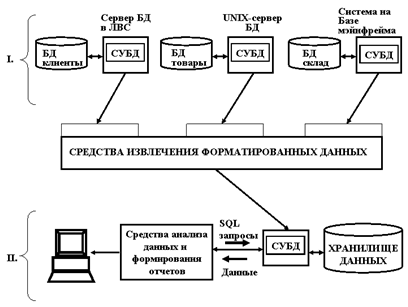
Деловые данные извлекаются из OLTP-системы предприятия, форматируются и проверяются, а затем помещаются в отдельную БД, предназначенную исключительно для делового анализа («хранилище»). Извлечение и форматирование данных можно выполнять периодически, в пакетном режиме во время наименьшей загрузки системы. Долго выполняющиеся запросы, связанные с деловым анализом, адресуются только к хранилищу данных и не требуют систем оперативной обработки транзакций.
Для удовлетворения специфических потребностей приложений, работающих с хранилищами данных и часто называемыми приложениями оперативной аналитической обработки (OLAP), стали появляться специальные СУБД. Ведущую роль в таких СУБД занимает SQL.
3. Методика проектирования логической модели базы данных
Проектирование логической модели БД целесообразно проводить с помощью ER-диаграммами (диаграмм Сущность-Связь). В данном вопросе рассматривается нотация ER-диаграмм и основные методы семантического моделирования данных.
Основные понятия ER-диаграмм
Определение 1. Сущность - это класс однотипных объектов, информация о которых должна быть учтена в модели.
Каждая сущность должна иметь наименование, выраженное существительным в единственном числе.
Примерами сущностей могут быть такие классы объектов как "Поставщик", "Сотрудник", "Накладная".
Каждая сущность в модели изображается в виде прямоугольника с наименованием (СЛАЙД 2):

Определение 2. Экземпляр сущности - это конкретный представитель данной сущности.
Например, представителем сущности "Сотрудник" может быть "Сотрудник Иванов".
Экземпляры сущностей должны быть различимы, т.е. сущности должны иметь некоторые свойства, уникальные для каждого экземпляра этой сущности.
Определение 3. Атрибут сущности - это именованная характеристика, являющаяся некоторым свойством сущности (СЛАЙД 3).
Наименование атрибута должно быть выражено существительным в единственном числе (возможно, с характеризующими прилагательными).
Примерами атрибутов сущности "Сотрудник" могут быть такие атрибуты как "Табельный номер", "Фамилия", "Имя", "Отчество", "Должность", "Зарплата" и т.п.
Атрибуты изображаются в пределах прямоугольника, определяющего сущность:

Определение 4. Ключ сущности - это неизбыточный набор атрибутов, значения которых в совокупности являются уникальнымидля каждого экземпляра сущности. Неизбыточность заключается в том, что удаление любого атрибута из ключа нарушается его уникальность (СЛАЙД 4).
Сущность может иметь несколько различных ключей.
Ключевые атрибуты изображаются на диаграмме подчеркиванием:
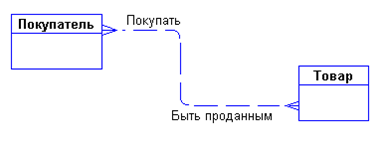
Определение 5. Связь - это некоторая ассоциация между двумя сущностями. Одна сущность может быть связана с другой сущностью или сама с собою (СЛАЙД 5)
Связи позволяют по одной сущности находить другие сущности, связанные с нею.
Например, связи между сущностями могут выражаться следующими фразами - "СОТРУДНИК может иметь несколько ДЕТЕЙ", "каждый СОТРУДНИК обязан числиться ровно в одном ОТДЕЛЕ".
Графически связь изображается линией, соединяющей две сущности:
Каждая связь имеет два конца и одно или два наименования. Наименование обычно выражается в неопределенной глагольной форме: "иметь", "принадлежать" и т.п. Каждое из наименований относится к своему концу связи. Иногда наименования не пишутся ввиду их очевидности.
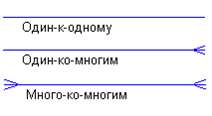
Каждая связь может иметь один из следующих типов связи (СЛАЙД5):

Связь типа один-к-одному означает, что один экземпляр первой сущности (левой) связан с одним экземпляром второй сущности (правой). Связь один-к-одному чаще всего свидетельствует о том, что на самом деле мы имеем всего одну сущность, неправильно разделенную на две.
Связь типа один-ко-многим означает, что один экземпляр первой сущности (левой) связан с несколькими экземплярами второй сущности (правой). Это наиболее часто используемый тип связи. Левая сущность (со стороны "один") называется родительской, правая (со стороны "много") - дочерней.
Связь типа много-ко-многим означает, что каждый экземпляр первой сущности может быть связан с несколькими экземплярами второй сущности, и каждый экземпляр второй сущности может быть связан с несколькими экземплярами первой сущности. Тип связи много-ко-многим является временным типом связи, допустимым на ранних этапах разработки модели. В дальнейшем этот тип связи должен быть заменен двумя связями типа один-ко-многим путем создания промежуточной сущности. Мощность связей может подписываться у концов связи (например, 1-к-5).
Каждая связь может иметь одну из двух модальностей связи (СЛАЙД5):
Модальность "может" означает, что экземпляр одной сущности может быть связан с одним или несколькими экземплярами другой сущности, а может быть и не связан ни с одним экземпляром.
Модальность "должен" означает, что экземпляр одной сущности обязан быть связан не менее чем с одним экземпляром другой сущности.
| <== предыдущая лекция | | | следующая лекция ==> |
| Погрешность базирования | | |
Дата добавления: 2021-02-19; просмотров: 214;
Поиск по сайту
Узнать еще
- CALS-технологии в автоматизированном производстве
- D-дисплеи на базе ЖК
- II. Базовые понятия музыкальной акустики
- III. Разработка базовых конкурентных стратегий и стратегий роста предприятия.
- IX.3. Современные ландшафты мира
- STEP – стандарт для описания данных об изделии
- VIII.ЮРИДИЧЕСКИЕ АДРЕСА И БАНКОВСКИЕ РЕКВИЗИТЫ СТОРОН
- Інститути та їх функції в економіці. Базисні інститути національної економіки

Публикации по технике и механике

Публикации по биологии

Публикации по информатике

Публикации по строительству

Публикации по физике

Публикации по химии

Публикации по электронике

Публикации по искусству

Публикации по истории
