Web 3.0 (Semantic Web)
Web 3.0 — это принципиально новый подход к обработке информации, представленной во Всемирной паутине. Web 3.0 в первую очередь подразумевает под собой иной подход к обработке информации сообществом пользователей. Если Web 1.0 предполагает веб-мастера в качестве поставщика контента, а Web 2.0 — сообщество равноправных пользователей, генерирующих контент в рамках тематического проекта, то Web 3.0 уже позволяет этим самым равноправным пользователям "выбирать" экспертов в заданной области (или в нескольких областях) и "наделять его властью". Такие общепризнанные эксперты-выдвиженцы постепенно расширяют свое влияние на сообщество, могут выступать его модераторами, управлять сообществом при помощи дополнительных прав и расширенных возможностей в рамках интернет-проекта. Это исключает возможность управления сообществом некомпетентных и малозначимых его участников, что является очень важным вещью — достаточно вспомнить «вебдванольное» равноправие на проекте Wikipedia, из-за которого ее создатель должен был более десятка раз исправлять свою собственную (!) биографию – пользователи считали, что в ней есть неточности и честно ее исправляли.
Также термином Web 3.0 часто называют концепцию семантической паутины (Semantic Web).
Семантическая паутина (англ. Semantic Web) — часть глобальной концепции развития сети Интернет, целью которой является реализация возможности машинной обработки информации, доступной во Всемирной паутине. Основной акцент концепции делается на работе с метаданными, однозначно характеризующими свойства и содержание ресурсов Всемирной паутины, вместо используемого в настоящее время текстового анализа документов. Термин впервые введён Тимом Бернерсом-Ли в мае 2001 года в журнале «Scientific American», и называется им «следующим шагом в развитии Всемирной паутины». В семантической паутине предполагается повсеместное использование, во-первых, унифицированных идентификаторов ресурсов (URI), а во-вторых — онтологий и языков описания метаданных.
Эта концепция была принята и продвигается Консорциумом W3 (Рис. 2). Для её внедрения предполагается создание сети документов, содержащих метаданные о ресурсах Всемирной паутины и существующей параллельно с ними. Тогда как сами ресурсы предназначены для восприятия человеком, метаданные используются машинами (поисковыми роботами и другими интеллектуальными агентами) для проведения однозначных логических заключений о свойствах этих ресурсов.
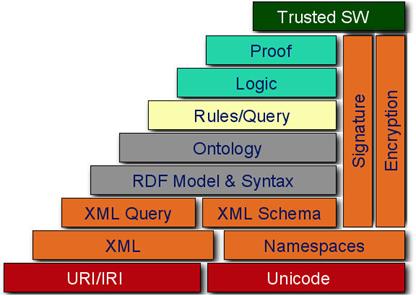
Рис. 2. Стек протоколов Semantic Web
Основная идея. Семантическая паутина — это надстройка над существующей Всемирной паутиной, которая призвана сделать размещённую в ней информацию более понятной для компьютеров. Машинная обработка возможна в семантической паутине благодаря двум её важнейшим характеристикам:
· Повсеместное использование унифицированных идентификаторов ресурсов (URI). Традиционная схема использования таких идентификаторов в современном Интернете сводится к установке ссылок, ведущих на объект, им адресуемый. Очевидным свойством такой ссылки является возможность «загрузки» объекта, на который она указывает. Таким объектом может быть веб-страница, файл произвольного содержания, фрагмент веб-страницы, а также неявное указание на обращение к реально существующему физическому ресурсу по протоколу, отличному от HTTP (например, ссылки mailto:). Концепция семантической паутины расширяет это понятие, включая в него ресурсы, недоступные для скачивания. Адресуемыми с помощью URI ресурсами могут быть, например, отдельные люди, города и другие географические сущности, художественные артефакты и т. д. К идентификатору предъявляются несколько простых требований: он должен быть уникальной строкой определённого формата, адресующей реально существующий объект.
· Повсеместное использование онтологий и языков описания метаданных. Современные методы автоматической обработки данных, доступных в Интернете, как правило, основаны на частотном и лексическом анализе текстового содержимого, которое прежде всего предназначено для восприятия человеком. В семантической паутине предлагается использовать форматы описания, доступные для машинной обработки (например, семейство форматов, часто упоминаемое в литературе как «Semantic Web family»: RDF, RDF Schema или RDF-S, и OWL), в свою очередь, использующие URI для адресации описываемых и описывающих объектов, а также онтологии и дескрипционные логики в качестве базовых математических формализмов.
Критика. Несмотря на все преимущества, предоставляемые семантической паутиной в случае её внедрения, существуют сомнения в возможности её полной реализации.
Практическая нереализуемость. Разные комментаторы высказывают различные причины, которые могут быть препятствием к этому, начиная с человеческого фактора (люди склонны избегать работы по поддержке документов с метаданными, открытыми остаются проблемы истинности метаданных, и т. д.), и заканчивая сложностью определения онтологии верхнего уровня (корня иерархии), критической для семантической паутины.
Дублирование информации. Необходимость описания метаданных так или иначе приводит к дублированию информации. Каждый документ должен быть создан в двух экземплярах: размеченным для чтения людьми, а также в машинно-ориентированном формате.
Невозможность получения коммерческой выгоды. Известно, что основное финансирование современных интернет-ресурсов (за исключением строго некоммерческих проектов) обеспечивают рекламодатели. Главный критерий, от которого зависит стоимость рекламного места — посещаемость сайта. Однако в случае реализации семантических поисковых систем, которые будут сами отбирать и сразу предоставлять нужную пользователю информацию, отпадает необходимость посещать сайт — источник материала, а значит пользователь не увидит рекламу, и как следствие прекратится финансирование интернет-проектов.
Дата добавления: 2016-06-18; просмотров: 3813;
Поиск по сайту

Публикации по технике и механике

Публикации по биологии

Публикации по информатике

Публикации по строительству

Публикации по физике

Публикации по химии

Публикации по электронике

Публикации по искусству

Публикации по географии

Публикации по медицине
