Самообучающиеся системы
В основе самообучающихся систем лежат методы автоматической классификации примеров ситуаций реальной практики (обучения на примерах). Примеры реальных ситуаций накапливаются за некоторый исторический период и составляют обучающую выборку. Эти примеры описываются множеством признаков классификации. Причем обучающая выборка может быть:
· «с учителем» когда для каждого примера задается в явном виде значение признака его принадлежности некоторому классу ситуаций (классообразующего признака);
· «без учителя» когда по степени близости значений признаков классификации система сама выдает классы ситуаций.
В результате обучения системы автоматически строятся обобщенные правила или функции, определяющие принадлежность ситуаций классам, которыми обученная система пользуется при интерпретации новых возникающих ситуаций. Таким образом, автоматически формируется база знаний, используемая при решении задач классификации и прогнозирования. Эта база знаний периодически автоматически корректируется по мере накопления опыта реальных ситуаций, что позволяет сократить затраты на ее создание и обновление.
Общие недостатки, свойственные всем самообучающимся системам, заключаются
в следующем:
· возможна неполнота и/или зашумленность (избыточность) обучающей выборки и, как следствие, относительная адекватность базы знаний возникающим проблемам;
· возникают проблемы, связанные с плохой смысловой ясностью зависимостей признаков и, как следствие, неспособность объяснения пользователям получаемых результатов;
· ограничения в размерности признакового пространства вызывают неглубокое описание проблемной области и узкую направленность применения.
Индуктивные системы. Обобщение примеров по принципу от частного к общему сводится к выявлению подмножеств примеров, относящихся к одним и тем же подклассам, и определению для них значимых признаков.
Процесс классификации примеров осуществляется следующим образом:
1. Выбирается признак классификации из множества заданных (либо последовательно, либо по какому-либо правилу, например, в соответствии с максимальным числом получаемых подмножеств примеров);
2. По значению выбранного признака множество примеров разбивается на подмножества;
3. Выполняется проверка, принадлежит ли каждое образовавшееся подмножество примеров одному подклассу;
4. Если какое-то подмножество примером принадлежит одному подклассу, т.е. у всех примеров подмножества совпадает значение классообразующего признака, то процесс классификации заканчивается (при этом остальные признаки классификации не рассматриваются);
5. Для подмножеств примеров с несовпадающим значением классообразующего признака процесс классификации признаков последовательной классификации, а в конечных узлах –значения признака принадлежности определенному классу. Пример построения дерева решений на основе фрагмента таблицы примеров
| Классобр. Признак | Признаки классификации | |||
| Цена | Спрос | Конкуренция | Издержки | Качество |
| Низкая | Низкий | Маленькая | Маленькие | Низкое |
| Высокая | Низкий | Маленькая | Большие | Высокое |
| Высокая | Высокий | Маленькая | Большие | Низкое |
| Высокая | Высокий | Маленькая | Маленькие | Высокое |
| Высокая | Высокий | Маленькая | Маленькие | Низкое |
| Высокая | Высокий | Маленькая | Большие | Высокое |


 [спрос] высокий [цена высокая]
[спрос] высокий [цена высокая]

 низкий _ [издержки] _ большие [цена высокая]
низкий _ [издержки] _ большие [цена высокая]




 маленькие [цена низкая]
маленькие [цена низкая]
Рис. Фрагмент дерева решений
Анализ новой ситуации сводится к выбору ветви дерева, которая полностью определяет эту ситуацию. Поиск решения осуществляется в результате последовательной проверки признаков классификации. Каждая ветвь дерева соответствует одному правилу решения:
Если Спрос = «низкий» и Издержки = «маленькие»
То Цена = «низкая»
Нейронные сети. В результате обучения на примерах строятся математические решающие функции (передаточные функции или функции активации), которые определяют зависимости между входными (Xi) и выходными (Yi) признаками (сигналами).
X1
W1
 X2 U
X2 U
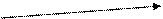
 W2 Σ f(u)
W2 Σ f(u)
X3
W3
Выход = f(Σ wixi)
Решающая функция – «нейрон»
Каждая такая функция, называемая по аналогии с элементарной единицей человеческого мозга – нейроном, отображает зависимость значения выходного признака (Y) от взвешенной суммы (U) значений входных признаков (Xi), в которой вес входного признака (Wi) показывает степень влияния входного признака на выходной:
Y=f(ΣW,*X)
Решающие функции используются в задачах классификации на основе сопоставления их значений при различных комбинациях значений входных признаков с некоторым пороговым значением. В случае превышения заданного порога считается, что нейрон сработал и таким образом распознал некоторый класс ситуаций. Нейроны используются и в задачах прогнозирования, когда по значениям входных признаков после их подстановки в выражение решающей функции получается прогнозное значение выходного признака.
 Функциональная зависимость может быть линейной, но, как правило, используется сигмоидальная форма, которая позволяет вычленять более сложные пространства значений выходных признаков. Такая функция называется логической.
Функциональная зависимость может быть линейной, но, как правило, используется сигмоидальная форма, которая позволяет вычленять более сложные пространства значений выходных признаков. Такая функция называется логической.
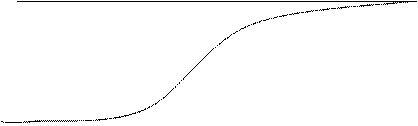 |
нейрон «вкл»

Логическая (сигмоидальная) функция
Нейроны могут быть связаны между собой, когда выход одного нейрона является входом другого. Таким образом, строится нейронная сеть, в которой нейроны, находящиеся на одном уровне, образуют слои.
Выходной слой Взвешенные связи

Нейронная сеть
Обучение нейронной сети сводится к определению связей (синапсов) между нейронами и установлению силы этих связей (весовых коэффициентов). Алгоритмы обучения нейронной сети упрощенно сводится к определению зависимости весового коэффициента связи двух нейронов от числа примеров, подтверждающих эту зависимость.
Наиболее распространенным алгоритмом обучения нейронной сети является алгоритм обратного распространения ошибки. Целевая функция по этому алгоритму должна обеспечить минимизацию квадрата ошибки в обучении по всем примерам:
Min Σ(Ti - Yi), где
Ti – заданное значение выходного признака по i-му примеру
Yi – вычисленное значение выходного признака по i-му примеру.
Сущность алгоритма обратного распространения ошибки сводится к следующему:
1. Задать произвольно небольшие начальные значения весов связей нейронов.
2. Для всех обучающих пар «значение входных признаков – значение выходного признака» (примеров из обучающей выборки) вычислить выход сети (Y).
3. Выполнить рекурсивный алгоритм, начиная с выходных узлов по направлению к первому скрытому слою, пока не будет достигнут минимальный уровень ошибки.
Вычислить веса на (t+1) шаге по формуле:
Wij(t=1)=Wij(t) + ŋδiXi, где
Wij(t) – все связи от скрытого i-го нейрона или от входа к j-му нейрону на шаге t;
Xi – выходное значение i-го нейрона;
ŋ – коэффициент скорости обучения;
δ – ошибка для j-го нейрона.
Если j-ый нейрон – выходной, то
δi = Yi(1 - Yi)(Ti - Yi)
Если j-ый нейрон находится в скрытом внутреннем слое, то
δi =Xj(1- Xj) Σ δkWjk, где
k-индекс всех нейронов в слое, расположенном вслед за слоем с j-ым нейроном.
Выполнить шаг 2.
Достоинство нейронных сетей перед инструктивным выводом заключается в решении не только классифицирующих, но и прогнозных задач. Возможность нелинейного характера функциональной зависимости выходных и входных признаков позволяет строить более точные классификации.
Сам процесс решения задач в силу проведения матричных преобразований проводится очень быстро. Фактически имитирует параллельный процесс прохода по нейронной сети в отличие от последовательного в индуктивных системах.
Нейронные сети могут быть реализованы и аппаратно в виде нейрокомпьютеров с ассоциативной памятью.
Системы, основанные на прецедентах (case-based reasoning). В этих системах база знаний содержит описание не обобщенных ситуаций, а собственно сами операции или прецеденты. Тогда поиск решения проблемы сводится к поиску по аналогии (абдуктивному выводу от частного к частному):
1. Получение подробной информации о текущей проблеме;
2. Сопоставление полученной информации со значениями признаков прецедентов из базы знаний;
3. Выбор прецедента из базы знаний, наиболее близко к рассматриваемой проблеме;
4. В случае необходимости выполняется адаптация выбранного прецедента к текущей проблеме;
5. Проверка корректности каждого полученного решения;
6. Занесение детальной информации о полученном решении в базу знаний.
Так же как и для индуктивных систем прецеденты описываются множеством признаков, по которым строятся индексы быстрого поиска. Но в отличие от индуктивных систем допускается нечеткий поиск с получение множества допустимых альтернатив, каждая из которых оценивается некоторым коэффициентом уверенности. Далее наиболее подходящие решения адаптируются по специальным алгоритмам к реальным ситуациям. Обучение системы сводится к запоминанию каждой новой обработанной ситуации с принятыми решениями в базе прецедентов.
Дата добавления: 2021-01-11; просмотров: 323;
Поиск по сайту
Узнать еще
- F45.38 другие органы или системы
- I. История возникновения и развития классно-урочной системы.
- I. Развитие Донбасса в условиях кризиса феодально-крепостнической системы
- I. Создание системы управленческого учета.
- III. Филогенез эндокринной системы.
- IV. Движение поездов при неисправности электрожезловой системы и порядок регулировки количества жезлов в жезловых аппаратах
- L.3. Состояние российской системы образования и необходимость ее
- T-FlexCAD (Топ Системы, Москва) и др.

Публикации по технике и механике

Публикации по биологии

Публикации по информатике

Публикации по строительству

Публикации по физике

Публикации по химии

Публикации по электронике

Публикации по искусству

Публикации по истории
