Преобразователи кодов
Преобразователем кодов (ПК) называют КЦУ, которое преобразует n-разрядные двоичные входные слова в m-разрядные двоичные выходные слова. Иногда ПК называют n, m-преобразователями. Рассмотренные ранее дешифраторы и шифраторы являются ПК некоторых частных видов, например, их можно использовать для преобразования чисел из одной позиционной системы счисления в другую.
Построение схемы ПК рассмотрим на конкретном примере. Пусть требуется построить преобразователь четырехразрядных двоично-десятичных цифр из кода 8421 в код 2421. УГО такого ПК представлено на рисунке 10.
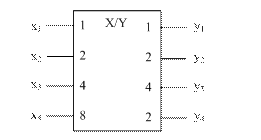
Рисунок 10 – Условное графическое обозначение преобразователя кода 8421 в код 2421
Соотношение входных и выходных слов задано таблицей истинности (таблица 3).
Таблица 3 – Таблица истинности преобразователя кода 8421 в код 2421
| Логические аргументы | Промежуточная переменная | Логические функции | ||||||
| x4 | x3 | x2 | x1 | zi | y4 | y3 | y2 | y1 |
| z0 | ||||||||
| z1 | ||||||||
| z2 | ||||||||
| z3 | ||||||||
| z4 | ||||||||
| z5 | ||||||||
| z6 | ||||||||
| z7 | ||||||||
| z8 | ||||||||
| z9 |
Имея таблицу истинности, можно использовать три подхода к синтезу ПК:
– преобразователь синтезируется как однокомпонентная минимизированная комбинационная схема с нерегулярной структурой (по общим правилам синтеза КЦУ);
– преобразователь синтезируется как слабо минимизированная комбинационная схема с частично регулярной структурой (на основе шифратора и дешифратора);
– преобразователь синтезируется как неминимизированная комбинационная схема с регулярной структурой (на основе постоянного запоминающего устройства).
Рассмотрим первый традиционный подход. По данным таблицы 3 заполним карты Карно (рисунок 11).
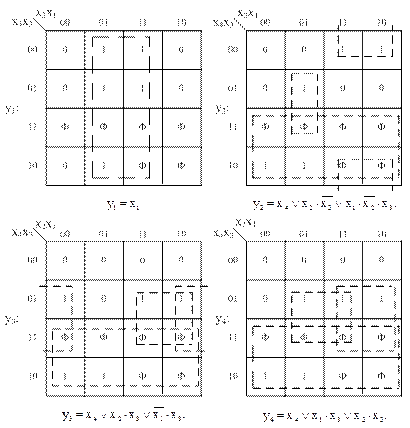
Рисунок 11 – Карты Карно для преобразователя кода 8421 в код 2421
Выполним соответствующие объединения заполненных клеток на рисунке 11 с учетом неопределенностей и запишем результаты минимизации в МДНФ:
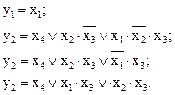 (8)
(8)
Далее по функциям системы (8) методом прямого замещения построим логическую схему ПК (рисунок 12).
На рисунке 12 проведена проверка правильности функционирования схемы для входного слова 0011. Так как на выходах схемы установилось выходное слово 0011, то ПК функционирует в соответствии с таблицей 3.
К достоинству первого подхода относится экономичность синтезируемой схемы по аппаратурным затратам, исчисляемым в условных транзисторах. Это означает, что схема будет занимать небольшую часть площади кристалла. Оценка схемы на рисунке 12 дает величину ЕПК (1) = 23 условных транзистора.
К недостатку этого подхода можно отнести то, что схема получилась нерегулярной (с неравным числом конъюнкторов в цепи каждого выхода, с перекрещивающимися связями), что делает ее нетехнологичной при изготовлении, неудобной для тестовых проверок.
Второй подход позволяет повысить регулярность структур ПК за счет некоторого увеличения аппаратурных затрат. Исходная информация для синтеза в том случае также содержится в таблице 3, в которой имеется столбец с промежуточной переменной zi (при первом подходе этот столбец не учитывался).
Левая и центральная части таблицы 3 представляют собой описание дешифратора, а правая и центральная части представляют собой таблицу кодирования некоторого шифратора. Таким образом, схема ПК в данном случае приобретает двухкомпонентную структуру вида «десятичный дешифратор-шифратор» (рисунок 13). Она несколько сложнее схемы на рисунке 12 (ЕПК(2)=77 условных транзисторов), но значительно проще для обозрения.
К недостатку полученной схемы следует отнести ее специализированность, что снижает массовость выпуска подобных схем и приводит к относительно высокой цене изделия.

Рисунок 12 – Логическая схема ПК 8421 в код 2421 в основном базисе
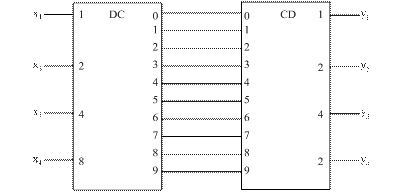
Рисунок 13 – Преобразователь кода с частично регулярной структурой
Третий подход позволяет значительно повысить регулярность структуры ПК и одновременно существенно расширить его функциональные возможности. В этом случае запрещается использовать специализированные компоненты. Таким образом, ПК должен содержать полный двоичный n-входной дешифратор и 2n-входной шифратор. В результате получается постоянное запоминающее устройство (ПЗУ). Следовательно, ПЗУ – это n, m-преобразователь с двухкомпонентной регулярной структурой, на выходе которого включен шифратор, формирующий m-разрядные слова.
Входное слово ПК в этом случае является адресом ячейки ПЗУ, в которой хранится соответствующее выходное слово. УГО ПК на ПЗУ представлено на рисунке 14. Оно представляет собой прямоугольник с n-входами и m-выходами, во внутреннем поле которого записана аббревиатура ROM (от англ. Read Only Memory).
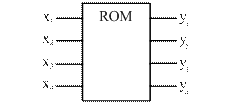
Рисунок 14 – Преобразователь кода на основе ПЗУ
ПЗУ имеет целый ряд недостатков (невозможность обновления записанной информации, аппаратурная избыточность при реализации тех или иных ПК и др.), однако в цифровой схемотехнике они очень широкого применяются благодаря широким функциональным возможностям (хранение констант, микропрограмм, программ начальной загрузки, кодопреобразование, выполнение арифметических и логических операций), регулярности структуры, а следовательно, высокой технологичности их изготовления.
Мультиплексоры
Мультиплексором называется КЦУ, которое обеспечивает альтернативную (поочередную) передачу данных от нескольких источников одному приемнику. Эта операция коммутации каналов называется мультиплексированием. Если требование альтернативности отсутствует, то задача мультиплексирования вырождается в случай логического сложения данных. При m источниках информации мультиплексор должен иметь m информационных входов, k=log2m адресных входов и один информационный выход. Разрядности каналов передачи могут быть различными, мультиплексоры для коммутации многоразрядных слов составляются из одноразрядных.
Принцип построения одноразрядных мультиплексоров рассмотрим на примере синтеза мультиплексора на четыре информационных входа (m=4). УГО такого мультиплексора (рисунок 15) представляет собой прямоугольник с аббревиатурой MUX (от англ. Multiplexer) во внутреннем поле.
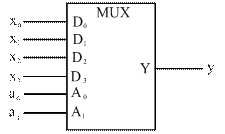
Рисунок 15 – Условное графическое обозначение одноразрядного мультиплексора для m=4
Входы А1, А0 служат для приема адреса источника, от которого подается информация в данный момент.
По приведенному описанию составим таблицу истинности для мультиплексора (таблица 4).
Таблица 4 – Таблица истинности одноразрядного мультиплексора для m=4
| Логические аргументы | Логическая функция | |||||
| x0 | x1 | x2 | x3 | а1 | а0 | y |
| x x | x x | x x | ||||
| x x | x x | x x | ||||
| x x | x x | x x | ||||
| x x | x x | x x |
Из таблицы 4 следует, что сигнал на выходе y является логической функцией шести аргументов, следовательно, в СДНФ эта функция содержит 32 конституенты единицы. Поэтому перепишем таблицу 4 в карту Карно (рисунок 16) для минимизации функции.
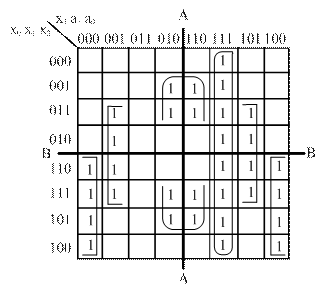
Рисунок 16 – Карта Карно для одноразрядного мультиплексора для m = 4
Выполним соответствующие объединения заполненных клеток и запишем результат минимизации в МДНФ:
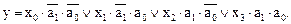 (9)
(9)
Логическая схема мультиплексора, построенная по функции (9), приведена на рисунке 17 а.
Схема получилась экономичной по аппаратурным затратам (ЕMUX = 20 условных транзисторов), достаточно быстродействующей (TMUX = 4 tзд. ЛЭ), но плохо структурированной.
Для структурирования схемы мультиплексора представим функцию (9) в виде:
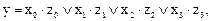 (10)
(10)
где 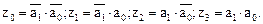 (11)
(11)
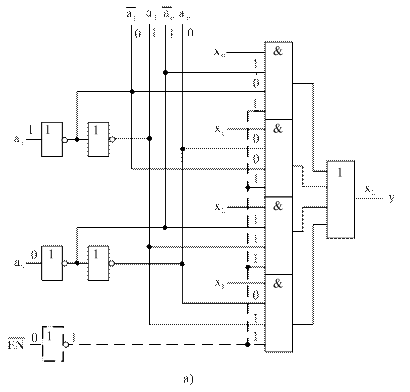
Примечание – Штриховой линией показаны цепи для организации входа разрешения работы 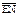 .
.
Рисунок 17 – Одноразрядный мультиплексор для m=4. Логическая схема неструктурированная (а) и структурированная (б)
Окончание рисунка 17
В этом случае в схеме мультиплексора (рисунок 17 б) выделяются два структурных компонента: управляемый коммутатор, описываемый функцией (10), и управляющий дешифратор, описываемый системой функций (11). Аппаратурные затраты на реализацию структурированного варианта мультиплексора составляют 24 условных транзистора, а быстродействие оценивается величиной 5 tзд. ЛЭ.
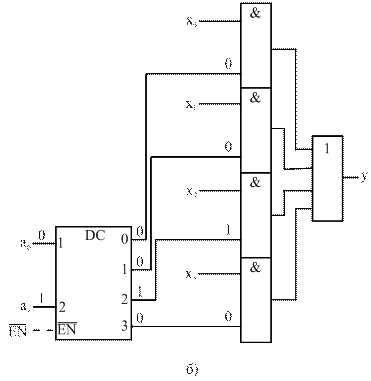
В стандартных сериях интегральных схем число информационных входов мультиплексоров m не более 16. Для наращивания числа информационных входов строят пирамидальную структуру из нескольких мультиплексоров с меньшим числом информационных входов, называемую мультиплексорным деревом. При этом первый ярус схемы представляет собой столбец, содержащий столько мультиплексоров, сколько необходимо для получения нужного числа информационных входов m. Все мультиплексоры столбца адресуются младшими разрядами k1 общего адресного кода (k1 = log2m1, где m1 – число информационных входов мультиплексоров первого яруса). Старшие разряды адресного кода, число которых равно k - k1 (k=log2m, где m - общее число информационных входов мультиплексорного дерева), используются во втором ярусе, мультиплексор которого обеспечивает поочередную работу мультиплексоров первого яруса на общий выходной канал.
Схема мультиплексорного дерева на 32 информационных входа на основе мультиплексоров на 8 информационных входов показана на рисунке 18. Три младших разряда адреса а2, а1, а0 подаются на адресные входы мультиплексоров первого яруса, а два старших разряда а4 и а3 – на адресные входы мультиплексора второго яруса. Например, адресный код 11001(2)=25(10) обеспечивает коммутацию выхода схемы с информационным входом x25 (рисунок 18).
Как отмечалось выше, универсальные логические модули (УЛМ) на основе мультиплексоров можно использовать для схемотехнической реализации различных логических функций. Универсальность их состоит в том, что для заданного числа аргументов можно настроить УЛМ на любую функцию. Для использования мультиплексора в качестве УЛМ следует изменить назначение его входов. На адресные входы следует подавать аргументы функции, а на информационные входы – сигналы настройки. Действительно, каждому набору аргументов соответствует передача на выход одного из сигналов настройки. Если этот сигнал есть значение функции на данном наборе аргументов, то задача решена.
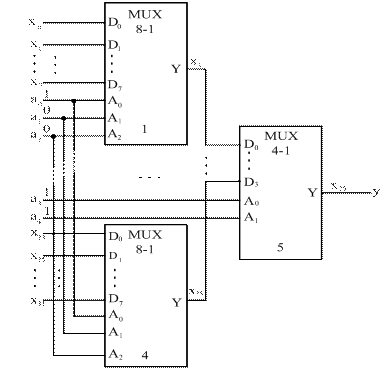
Рисунок 18 – Схема наращивания числа информационных входов мультиплексора
На рисунке 19 показан пример воспроизведения функции неравнозначности 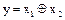 с помощью мультиплексора «4-1» при настройке УЛМ константами.
с помощью мультиплексора «4-1» при настройке УЛМ константами.
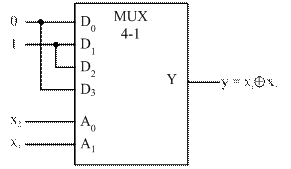
Рисунок 19 – Схема реализации неравнозначности при настройке УЛМ константами
Большое число настроечных входов затрудняет реализацию УЛМ. Для УЛМ, расположенных внутри кристалла, можно вводить код настройки последовательно в регистр сдвига, к разрядам которого подключены входы настройки. Тогда будет только один внешний вход настройки, но настройка будет занимать не один, а 2n тактов (где n – число аргументов). Существуют и другие более сложные способы настройки УЛМ [4].
Демультиплексоры
Демультиплексором называется КЦУ, которое обеспечивает альтернативную (поочередную) передачу данных от одного источника нескольким адресатам (приемникам). Эта операция коммутации каналов называется демультиплексированием. При m адресатах демультиплексор должен иметь один информационный вход, k≥log2m адресных входов и m информационных выходов.
В дальнейшем будем рассматривать одноразрядные демультиплексоры, осуществляющие обработку (коммутацию) одного бита информации. При необходимости демультиплексирования n-разрядных слов надо использовать n демультиплексоров. Если требование альтернативности отсутствует, то задача демультиплексирования вырождается в случай разветвления электрической цепи.
УГО одноразрядного демультиплексора для m = 4 приведено на рисунке 20 и представляет собой прямоугольник с аббревиатурой DMUX (от англ. Demultiplexer) во внутреннем поле. Входы А1,А0 служат для приема адреса абонента, которому предназначена информация в данный момент.
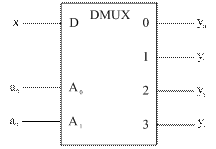
Рисунок 20 – Условное графическое обозначение одноразрядного демультиплексора для m = 4
По приведенному описанию составим таблицу истинности для мультиплексора (таблица 5).
Таблица 5 – Таблица истинности одноразрядного демультиплексора для m = 4
| Логические аргументы | Логические функции | |||||
| x | a1 | a0 | y0 | y1 | y2 | y3 |
По данным таблицы 5 запишем логические функции в СДНФ, которые описывают работу демультиплексора:
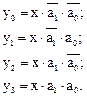 (12)
(12)
Функции получились простыми, и минимизация не требуется. Логическая схема одноразрядного демультиплексора для m = 4, построенная по системе функций (12), показана на рисунке 21 а (штриховой линией показаны цепи для организации входа разрешения).
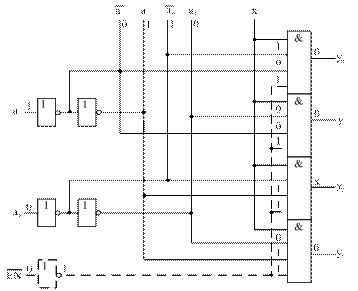
а)
б)
Рисунок 21 – Одноразрядный демультиплексор. Логическая схема неструктурированная (а) и структурированная (б)
Анализ схемы, представленной на рисунке 21 а, показывает, что одноразрядный демультиплексор фактически является двоичным дешифратором (вход Х может выполнять функцию входа разрешения). Поэтому в интегральном исполнении обычно выпускаются дешифраторы-демультиплексоры. Схема на рисунке 21 а плохо структурирована, так как в ней нет структурных компонентов промежуточного уровня. Аппаратурные затраты на реализацию такого демультиплексора оцениваются величиной ЕDMUX = 16 условных транзисторов. Быстродействие схемы с учетом инверторов оценивается величиной TDMUX = 3 tзд. ЛЭ.
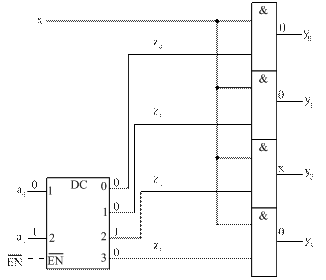
Схему демультиплексора можно структурировать. Для этого преобразуем логические функции (12) следующим образом:
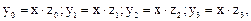 (13)
(13)
где (14)
В этом случае также выделяются два структурных компонента схемы: управляемый коммутатор, описываемый системой функций (13), и управляющий дешифратор, описываемый системой функций (14).
Структурная схема демультиплексора (рисунок 21 б) более технологична в изготовлении, более проста при поиске неисправностей. Аппаратурные затраты оцениваются величиной ЕDMUX = 20 условных транзисторов, а быстродействие – TDMUX = 4tзд. ЛЭ. Но на практике чаще используется неструктурированная схема (рисунок 21 а), поскольку она более быстродействующая и требует меньше аппаратурных затрат.
Число выходов демультиплексоров в интегральном исполнении не превышает 16. Для наращивания числа выходов демультиплексора строят демультиплексорное дерево аналогично схеме на рисунке 5. Разница в том, что входы разрешения работы будут играть роль информационных входов дешифраторов-демультиплексоров. В рассмотренном примере для адреса 11001 поток данных с информационного входа будет передаваться на выход y25.
Мультиплексоры и демультиплексоры широко применяются в микропроцессорной технике, например, для стыковки внутренней шины данных с внешней шиной меньшей разрядности.
Кроме того, пара мультиплексор-демультиплексор представляет собой электронный коммутатор, находящий широкое использование в информационных сетях различного вида, например, в коммутационных полях цифровых коммутационных станций.
Двоичные сумматоры
Одноразрядным двоичным сумматором (ОДС) называется КЦУ, которое предназначено для сложения двух одноразрядных двоичных чисел с учетом переноса из соседнего младшего разряда. УГО ОДС показано на рисунке 22.
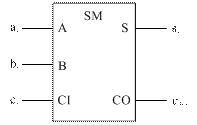
Рисунок 22 – Условное графическое обозначение ОДС
ОДС имеет три входа для подачи разрядов слагаемых ai, bi и переноса из соседнего младшего разряда ci. На выходах ОДС формируется сумма si и перенос в соседний старший разряд ci+1. Принцип работы ОДС поясняется следующей таблицей истинности (таблица 6).
Таблица 6 – Таблица истинности ОДС
| Логические аргументы | Логические функции | |||
| ai | bi | ci | si | ci+1 |
Минимизируем логические функции si и ci+1 табличным методом с помощью карт Карно. Для этого по данным таблицы 6 заполним карты Карно (рисунок 23).
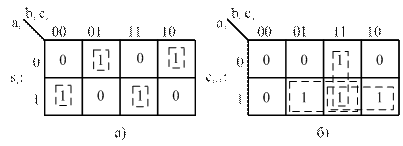
Рисунок 23 – Минимизация функций ОДС. Карты Карно для выхода суммы si (а) и выхода переноса ci+1 (б)
Выполним необходимые объединения и запишем результат минимизации в МДНФ:
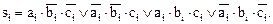 ….(15)
….(15)
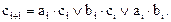 ….(16)
….(16)
Очевидно, что функция si не поддается минимизации, так как на рисунке 23 а все конституенты единицы изолированы. Логическая схема ОДС, построенная по функциям (15) и (16), показана на рисунке 24.
Многоразрядные двоичные сумматоры (МДС) в зависимости от способа ввода кодов слагаемых делятся на два типа: последовательного действия и параллельного действия. В МДС последовательного действия коды чисел вводятся в последовательной форме, т.е. разряд за разрядом, начиная с младшего. В МДС параллельного действия каждое слагаемое подается в параллельной форме, т.е. одновременно всеми разрядами.
Логическая схема МДС последовательного действия (рисунок 25) состоит из одноразрядного двоичного сумматора (ОДС), выход СО (от англ. Carry Output) которого соединен со входом СI (от англ. Carry Input) через D-триггер. Сдвиговые регистры 1 и 2 служат для подачи на входы сумматора разрядов слагаемых, а регистр 3 – для приема результата суммирования.
Операция суммирования во всех разрядах слагаемых осуществляется с помощью одного и того же ОДС.
С первым тактовым импульсом (ТИ) на входы ОДС поступают из регистров 1 и 2 цифры первого разряда слагаемых a0 и b0, а из D-триггера на вход СI подается нулевой сигнал. Суммируя поданные на входы цифры, ОДС формирует первый разряд суммы s0, выдаваемый на вход регистра 3, и перенос c1, принимаемый в D-триггер. Второй ТИ осуществляет в регистрах сдвиг на один разряд вправо, при этом на входы ОДС подаются цифры второго разряда слагаемых a1, b1 и c1. Получающаяся цифра второго разряда суммы s1 вдвигается в регистр 3, перенос c2 принимается в D-триггер и т.д.
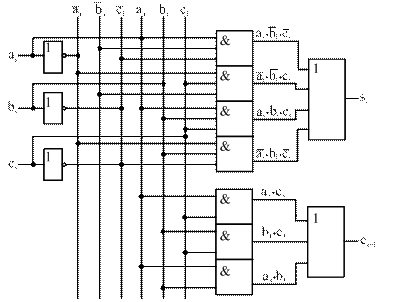
Рисунок 24 – Логическая схема ОДС
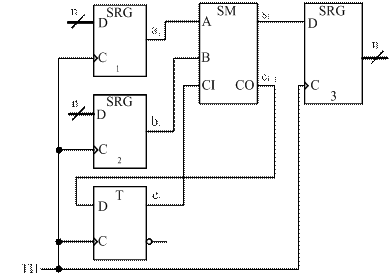
Рисунок 25 – Логическая схема МДС последовательного действия
Достоинством МДС последовательного действия является малый объем оборудования, требуемый для его построения, а недостатком – низкое быстродействие, так как время суммирования TSM пропорционально разрядности слагаемых.
МДС параллельного действия в зависимости от способа передачи переносов от младших разрядов в старшие могут быть двух типов:
– с последовательным переносом;
– с параллельным (ускоренным) переносом.
Логическая схема МДС параллельного действия с последовательным переносом (рисунок 26) состоит из отдельных разрядов, каждый из которых содержит ОДС.
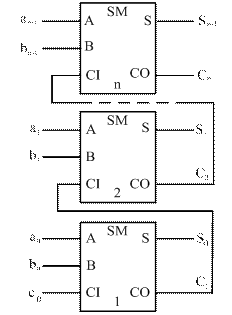
Рисунок 26 – Логическая схема МДС параллельного действия с последовательным переносом
При подаче слагаемых цифры их разрядов поступают на соответствующие ОДС. Каждый из ОДС формирует на своих выходах цифру соответствующего разряда суммы и перенос в соседний старший разряд. Сигнал переноса в каждом разряде формируется после того, как будет сформирован и передан сигнал переноса из предыдущего разряда. В худшем случае, возникший в младшем разряде перенос может последовательно вызывать переносы во всех остальных разрядах. При этом время передачи переносов TC = n tC ОДС, где tC ОДС – задержка распространения в одном разряде. Таким образом, последовательный перенос в МДС параллельного действия не обеспечивает высокое быстродействие.
Для обеспечения высокого быстродействия в МДС параллельного действия сигналы переносов формируются одновременно для всех разрядов с помощью блока ускоренного переноса. На рисунке 27 показана функциональная схема четырехразрядной секции МДС параллельного действия с параллельным переносом.
При этом разрядные сумматоры не содержат цепей формирования переносов, они формируют только сумму si и функции Gi, Pi, для получения которых переносы не требуются. Эти вспомогательные функции генерации переноса 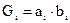 и распространения переноса
и распространения переноса 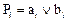 необходимы для формирования переносов в блоке ускоренного переноса GRP (рисунок 27). Исходя из этого, выражение (16) можно представить в следующем виде:
необходимы для формирования переносов в блоке ускоренного переноса GRP (рисунок 27). Исходя из этого, выражение (16) можно представить в следующем виде:
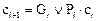 . (17)
. (17)
Из выражения (17) следует, что сигнал переноса на выходе i-го разряда генерируется самим разрядом (Gi = 1) при 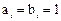 независимо от результата переноса из соседнего младшего разряда. Следовательно, можно передавать сигнал переноса для обработки старших разрядов, не дожидаясь окончания формирования переносов из младших разрядов. Однако, если только один из сигналов ai, bi равен единице, то перенос в следующий разряд будет иметь место только при наличии переноса из предыдущего разряда (Pi = 1, ci = 1). Таким образом, сигналы переноса в каждом разряде формируются одновременно в соответствии с выражением (17).
независимо от результата переноса из соседнего младшего разряда. Следовательно, можно передавать сигнал переноса для обработки старших разрядов, не дожидаясь окончания формирования переносов из младших разрядов. Однако, если только один из сигналов ai, bi равен единице, то перенос в следующий разряд будет иметь место только при наличии переноса из предыдущего разряда (Pi = 1, ci = 1). Таким образом, сигналы переноса в каждом разряде формируются одновременно в соответствии с выражением (17).
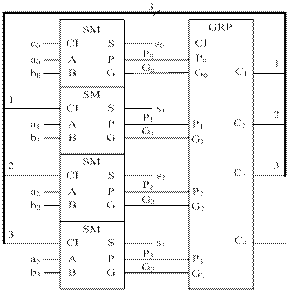
Рисунок 27 – Функциональная схема четырехразрядной секции сумматора с ускоренным (параллельным) переносом
Дата добавления: 2021-01-11; просмотров: 477;
Поиск по сайту
Узнать еще
- Cпециализированные преобразователи
- DC-AC преобразователи. Двухактный инвертор.
- Абсолютные и дифференциальные вихретоковые преобразователи
- АКТИВНЫЕ ПРЕОБРАЗОВАТЕЛИ СОПРОТИВЛЕНИЯ
- Аналого цифровые преобразователи
- Аналого-цифровые и цифро-аналоговые преобразователи
- Аналого-цифровые и цифро-аналоговые преобразователи
- Аналого-цифровые преобразователи

Публикации по технике и механике

Публикации по биологии

Публикации по информатике

Публикации по строительству

Публикации по физике

Публикации по химии

Публикации по электронике

Публикации по искусству

Публикации по истории
