Кодирование в канале
Ранее были определены операции кодирования источников сообщений. Если полученную последовательность сигналов передавать через канал потребителю, то часть сигналов может быть искажена. Чтобы обнаружить и исправить искажения вводится некоторая избыточность информации в передаваемые кодовые комбинации. Процедура введения избыточности в кодовые комбинации называется помехоустойчивым кодированием или кодированием в канале и выполняется кодером канала. Коды, позволяющие исправлять ошибки, называются корректирующими.
Для восстановления первоначального кода служит декодер канала. На рисунке 5.1 приведена модель передачи информации с применением кодера и декодера канала.
 |
Помехи могут исказить
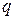 символов в кодовом слове. Если искаженные символы независимы и вероятность искажения одного символа равна
символов в кодовом слове. Если искаженные символы независимы и вероятность искажения одного символа равна 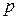 , то вероятность ошибки кратности равна
, то вероятность ошибки кратности равна
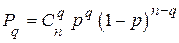 , (5.1)
, (5.1)
где 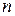 - число двоичных символов в передаваемой кодовой комбинации.
- число двоичных символов в передаваемой кодовой комбинации.
Обычно 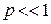 . Из приведённой формулы видно, что наиболее вероятны одиночные ошибки и ошибки малой кратности. Поэтому разрабатывались корректирующие коды, определяющие одиночные ошибки и ошибки кратности 2, 3, 4.
. Из приведённой формулы видно, что наиболее вероятны одиночные ошибки и ошибки малой кратности. Поэтому разрабатывались корректирующие коды, определяющие одиночные ошибки и ошибки кратности 2, 3, 4.
При декодировании принятой кодовой комбинации возникают две проблемы:
- обнаружение ошибки,
- исправление ошибки.
Естественно, что вторая задача включает первую, но они различаются по методам обработки кодовой последовательности и по числу символов, необходимых для обнаружения и исправления ошибок.
Пусть на вход кодера канала поступают 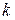 - разрядные кодовые комбинации и можно образовать
- разрядные кодовые комбинации и можно образовать 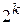 - кодовых комбинаций. На выходе кодера канала получаем - разрядные кодовые комбинации, которые образуют
- кодовых комбинаций. На выходе кодера канала получаем - разрядные кодовые комбинации, которые образуют 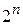 - кодовых комбинаций,
- кодовых комбинаций, 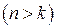 ,и они передаются в канал связи. В множестве кодовых комбинаций содержится кодовых комбинаций, которые соответствуют кодовым комбинациям на входе кодера канала. Назовём их разрешёнными кодовыми комбинациями, остальные - - запрещенными (неразрешёнными) кодовыми комбинациями.
,и они передаются в канал связи. В множестве кодовых комбинаций содержится кодовых комбинаций, которые соответствуют кодовым комбинациям на входе кодера канала. Назовём их разрешёнными кодовыми комбинациями, остальные - - запрещенными (неразрешёнными) кодовыми комбинациями.
 Ошибка при декодировании обнаруживается, если декодируемый код попадет в область неразрешённых кодовых комбинаций, рисунок 5.2.
Ошибка при декодировании обнаруживается, если декодируемый код попадет в область неразрешённых кодовых комбинаций, рисунок 5.2.
В результате передачи информации на выходе канала связи возможны различные комбинации кодов на входе кодера канала и на выходе канала связи. Их число равно . В число этих комбинаций входят:
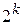 - число безошибочных переходов (безошибочного декодирования),
- число безошибочных переходов (безошибочного декодирования),
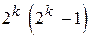 - число переходов в другие (ошибочные) разрешённые кодовые комбинации,
- число переходов в другие (ошибочные) разрешённые кодовые комбинации,
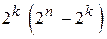 - число переходов в неразрешённые кодовые комбинации. Всего различных вариантов кодовых комбинаций будет
- число переходов в неразрешённые кодовые комбинации. Всего различных вариантов кодовых комбинаций будет
+ + = .
Те кодовые комбинации из разрешённых, которые перешли в область запрещённых кодовых комбинаций, могут быть обнаружены безошибочно.
Доля обнаруженных ошибочных кодовых комбинаций по отношению к общему числу вариантов приема сигналов равна
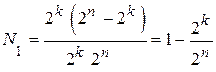 .
.
Рассмотрим возможность исправления ошибок. Разобьем все неразрешённые кодовые комбинации на подмножеств. Сопоставим каждому разрешённому коду одно определённое подмножество из области запрещённых кодов. В этом подмножестве должны содержаться коды, указывающие ошибки в принятой кодовой комбинации. Организация этих подмножеств зависит от числа исправляемых ошибок и методов кодирования-декодирования. Доля исправляемых ошибок по отношению к общему числу обнаруживаемых ошибок равна
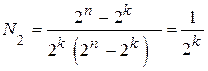 .
.
Если рассмотреть геометрическую интерпретацию кодов, то кодовые комбинации будут представлять вершины -мерного куба.
Мерой различия двух кодовых комбинаций является кодовое расстояние 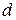 , равное числу символов, которыми отличаются две кодовые комбинации, и названное расстоянием Хемминга. С геометрической точки зрения кодовое расстояние – это число рёбер многомерного куба, которое необходимо пройти от одной кодовой комбинации к другой.
, равное числу символов, которыми отличаются две кодовые комбинации, и названное расстоянием Хемминга. С геометрической точки зрения кодовое расстояние – это число рёбер многомерного куба, которое необходимо пройти от одной кодовой комбинации к другой.
 Пример 5.1. Чтобы найти расстояние Хемминга между двумя кодами необходимо сложить по модулю два обе кодовые комбинации. Число «1» в результате суммирования равно кодовому расстоянию. В приведённом примере =5.
Пример 5.1. Чтобы найти расстояние Хемминга между двумя кодами необходимо сложить по модулю два обе кодовые комбинации. Число «1» в результате суммирования равно кодовому расстоянию. В приведённом примере =5.
Другим параметром, характеризующим кодовую комбинацию является вес кода – P - число«1» в кодовой комбинации.
Рассмотрим, как влияет кодовое расстояние на обнаружение и исправление ошибок. Положим, d = 1, т.е. все кодовые комбинации являются разрешёнными кодовыми комбинациями. Любая ошибка трансформирует одну кодовую комбинацию в другую.
Увеличим кодовое расстояние на единицу. Если расстояние между кодовыми комбинациями равно 2, то существуют запрещённые кодовые комбинации, т.е. при однократной ошибке, чтобы перейти из одной вершины гиперкуба к другой, на которой расположены разрешённые коды, нужно пройти по двум рёбрам. Но между двумя разрешёнными кодами на вершинах гиперкуба обязательно находится запрещённая кодовая комбинация. И любая однократная ошибка приводит к запрещённой кодовой комбинации, которая обнаруживается декодером.
 На рисунке 5.3 изображён трёхмерный куб, на вершинах которого размещены трёхразрядные коды. Разрешёнными кодами являются 000, 011, 101, 110. Остальные коды 001, 010, 100, 111 ‑ запрещённые. Следует обратить внимание:
На рисунке 5.3 изображён трёхмерный куб, на вершинах которого размещены трёхразрядные коды. Разрешёнными кодами являются 000, 011, 101, 110. Остальные коды 001, 010, 100, 111 ‑ запрещённые. Следует обратить внимание:
-‑ минимальное кодовое расстояние для обнаружения одиночной ошибки равно 2,
-‑ число «1» в неразрешённых кодовых комбинациях – нечётное. Поэтому иногда процедуру обнаружения одиночной ошибки называют проверкой на чётность.
В общем случае для обнаружения q кратной ошибки минимальное кодовое расстояние должно удовлетворять неравенству
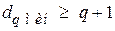 (5.2)
(5.2)
Для исправления ошибок число проверочных кодов должно быть больше, так как проверяется каждый символ в разрешённой кодовой комбинации на наличие ошибки.
В общем случае для исправления ошибок кратности 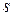 минимальное кодовое расстояние меду разрешёнными кодовыми комбинациями должно удовлетворять соотношение
минимальное кодовое расстояние меду разрешёнными кодовыми комбинациями должно удовлетворять соотношение
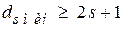 (5.3)
(5.3)
Например, если необходимо передать символы «0» и «1» с учётом исправления возникших ошибок, то согласно неравенству (5.3), надо использовать коды с минимальным кодовым расстоянием, равным 3. Наиболее наглядным является использование кодов 000 и 111 для передачи символов «0» и «1», (рисунок 5.4).
В трёхразрядном коде две кодовые комбинации (000, 111) являются разрешёнными. Остальные кодовые комбинации – запрещенные. При наличии однократной ошибки в кодах 000 или 111 декодер обнаруживает их и исправляет.
 С точки зрения геометрической интерпретации -разрядный двоичный код расположен на вершинах -мерного куба, представляющих как разрешённые, так и запрещённые кодовые комбинации. Если интерпретировать число исправляемых символов как радиус -мерной сферы, из неравенства (5.3) можно получить условие
С точки зрения геометрической интерпретации -разрядный двоичный код расположен на вершинах -мерного куба, представляющих как разрешённые, так и запрещённые кодовые комбинации. Если интерпретировать число исправляемых символов как радиус -мерной сферы, из неравенства (5.3) можно получить условие
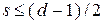 ,
,
определяющее подмножество разрешённых комбинаций, находящихся в -мерной сфере радиуса , с кодовым расстоянием, не превышающим 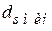 .
.
Для обнаружения всех ошибок кратности и исправления ошибок кратности расстояние между разрешёнными кодовыми комбинациями должно выбираться из условия
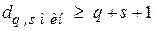 . (5.4)
. (5.4)
Приведённые формулы получены для исправления независимых ошибок. Они дают завышенные значения минимального кодового расстояния при помехе, коррелированной с сигналом.
Если длительность помехи превышает длительность сигнала, то ошибка возникает подряд в нескольких разрядах передаваемого кода. Ошибки подобного рода называются пачками или пакетами ошибок.
Дата добавления: 2022-04-12; просмотров: 285;
Поиск по сайту

Публикации по технике и механике

Публикации по биологии

Публикации по информатике

Публикации по строительству

Публикации по физике

Публикации по химии

Публикации по электронике

Публикации по искусству

Публикации по географии

Публикации по медицине
