КОЛИЧЕСТВЕННЫЕ ОЦЕНКИ ИНФОРМАЦИОННЫХ ОБЪЕКТОВ И ПРОЦЕССОВ
2.1. Подходы к определению количества информации
Одним из фундаментальных понятий теории информации является понятиеколичества информации. В связи с этим возникает вопрос об установлении меры количества информации.
Существует множество различных подходов и, следовательно, различных мер количества информации. Основными из этих подходов являются структурный, статистический и семантический подходы.
При структурномпоходе рассматривается строение и структура массивов информации и их измерение простым подсчетом максимально возможного количества информационных элементов, которое определяется этой структурой. Под информационными элементами понимаются неделимые частицы – кванты информации в дискретных моделях реальных информационных комплексов, а также элементы алфавитов в числовых системах. При структурном подходе различают геометрическую, комбинаторную и аддитивную меры информации.
Геометрической мерой определяется потенциальное, т.е. максимально возможное количество информации в заданных структурных габаритах, называемое информационной емкостью информационной системы. Информационная емкость может быть представлена числом, показывающим, какое количество квантов содержится в массиве информации.
К комбинаторной мере целесообразно прибегать тогда, когда требуется оценить возможность передачи информации при помощи различных комбинаций информационных элементов. Образование комбинаций есть одна из форм кодирования информации. Количество информации в комбинаторной мере вычисляется как количество комбинаций элементов. Таким образом, оценке подвергается комбинаторное свойство потенциального структурного разнообразия информационных систем. Комбинирование возможно в системах с неодинаковыми элементами, переменными связями или разнообразными позициями.
Наибольшее распространение получила аддитивнаямера, так называемая мера Хартли, измеряющая количество информации в двоичных единицах. Таким образом, структурный подход применяется для оценки потенциальных возможностей информационной системы вне зависимости от условий ее применения.
При статистическом подходе учитывается вероятностный характер появления того или иного сообщения и устанавливается зависимость количества информации, содержащегося в сообщении, от вероятности появления этого сообщения. Таким образом, статистический подход учитывает конкретные условия применения информационных систем.
С другой стороны, при статистическом подходе совершенно не учитывается смысловое содержание и субъективная ценность сообщения.
Для оценки этих и других подобных характеристик используется семантическийподход к установлению количественной меры информации. Семантический подход вводит меры содержательности, целесообразности и существенности информации.
Оценка содержательности информации требует формализации смысла. За основу описания объекта берется атомарное, т.е неделимое предложение или квант сообщения. Мерой измерения смысла являются функции истинности и ложности логических высказываний. Эти функции имеют формальное сходство с функциями вероятности события и его отрицания в теории вероятностей. Отличие вероятностной оценки от логической состоит в том, что в первом случае учитывается вероятность реализации тех или иных событий, а во втором – меры истинности или ложности событий, что приближает их к оценке смысла информации.
В качестве меры целесообразностиинформации предлагается использовать изменение вероятности достижения цели при получении информации. Полученная информация может не изменять вероятность достижения цели, и в этом случае мера ее целесообразности равна нулю, она может уменьшать вероятность достижения цели и тогда будет равна отрицательной величине, или увеличивать вероятность достижения цели и принимать положительное значение.
Функция существенности отражает степень важности информации о том или ином значении параметра события с учетом времени и пространства.
В настоящем курсе будет рассматриваться только статистический подход к установлению количественной меры информации. Это объясняется тем, что статистический подход так или иначе включает в себя структурный подход в качестве частного предельного случая, а основы семантического подхода являются предметом изучения в последующих дисциплинах учебного плана специальности.
2.2. Основы статистического подхода к определению количества информации
Интуитивно понятно, что количество информации, которое получает адресат, приняв сообщение, некоторым образом связано с априорной неопределенностью (доопытной, существовавшей до получения сообщения), которая, в свою очередь, зависит от числа возможных сообщений. Чем больше число возможных сообщений, тем больше априорная неопределенность получения одного из них и тем большее количество информации получает адресат, когда эта неопределенность снимается после получения сообщения.
Первая попытка ввести научно обоснованную меру количества информации была сделана в 1928 году Р. Хартли. Он предложил и обосновал количественную меру, позволяющую сравнивать способность различных систем передавать информацию. Эта мера подходит как для систем передачи, так и для систем хранения информации, поэтому она явилась отправной точкой для создания теории информации.
Естественным требованием, предъявляемым к информационной мере, является ее аддитивность: количество информации, которое можно сохранить в двух однотипных ячейках, должно быть в два раза больше, а в n одинаковых ячейках в n раз больше, чем в одной ячейке. Если ячейка для хранения информации имеет m возможных состояний, то две такие ячейки будут иметь m2 возможных состояний, а n одинаковых ячеек – mn возможных состояний. Следовательно, существует экспоненциальная зависимость между числом возможных состояний и числом ячеек. Учитывая эту зависимость, для количественной оценки способности системы хранить или передавать информацию Хартли ввел логарифмическую меру информационной емкости
Ih=log m, (2.1)
где m -число различных состояний системы. Такая мера удовлетворяет требованию аддитивности. Емкость устройства, состоящего из n ячеек и имеющего mn состояний, равна емкости одной ячейки, умноженной на число ячеек
C= log mn=n log m.
За единицу измерения информационной емкости принята двоичная единица – бит, равная емкости одной ячейки с двумя возможными состояниями.
Хартли ограничился рассмотрением информационной емкости как величины характеризующей физическую систему. Эта оценка дает представление о потенциальной максимально возможной информационной емкости информационной системы, в ней не учтены вероятности различных состояний. Таким образом, мера Хартли, строго говоря, является не статистической, а структурной мерой количества информации.
Дальнейшее развитие теория информации получила в трудах К.Шеннона, который ввел в нее понятия неопределенности и энтропии. Он ограничил применимость формулы Хартли (2.1) лишь тем случаем, когда все m исходов опыта X (т.е. состояний системы) равновероятны. В этом случае вероятность любого исхода 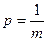 и тогда формулу Хартли (2.1.) можно переписать в следующем виде
и тогда формулу Хартли (2.1.) можно переписать в следующем виде
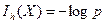 . (2.2.)
. (2.2.)
Принципиальное отличие этой формулы от (2.1.) состоит в том, что она показывает, что неопределенность исхода зависит от вероятности исхода.
Далее Шеннон применил эту формулу к разновероятным событиям, усреднив затем полученные неопределенности по всем исходам.
Для опыта X = {x1,. . . xm}, где x1,. . . xm - возможные исходы с вероятностями p1,. . . pm, неопределенность каждого исхода -logp1,. . . -logpm, а математическое ожидание по формуле
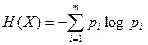 . (2.3.)
. (2.3.)
Получаемую по формуле (2.3) величину Шеннон назвал энтропией.
Таким образом, неопределенность каждой ситуации характеризуется величиной, называемой энтропией. Понятие энтропии существует в ряде областей знаний. Энтропия в термодинамике означает вероятность теплового состояния вещества, в математике – степень неопределенности ситуации или задачи, в теории информации – способность источника отдавать информацию. Все эти понятия родственны между собой. Так, например, согласно второму закону термодинамики энтропия замкнутого пространства выражается как 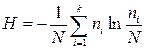 , где N - общее количество молекул в данном пространстве, ni - количество молекул, имеющих скорость vi. Но
, где N - общее количество молекул в данном пространстве, ni - количество молекул, имеющих скорость vi. Но 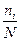 есть частоты событий, следовательно, вероятности того, что молекулы имеют скорость vi ,равна
есть частоты событий, следовательно, вероятности того, что молекулы имеют скорость vi ,равна 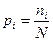 . Тогда
. Тогда 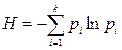 , что аналогично (2.3). Выбор основания логарифма несуществен, поскольку определяет лишь единицы измерения энтропии.
, что аналогично (2.3). Выбор основания логарифма несуществен, поскольку определяет лишь единицы измерения энтропии.
Поясним далее соотношение понятий энтропии и количества информации.
В соответствии с определением понятия энтропия является мерой априорной неопределенности, существовавшей до получения сообщения. Под количеством информации, содержащимся в сообщении, понимается мера снятой неопределенности после получения сообщения.
Предположим, что до получения сообщения ситуация характеризовалась энтропией H1, после получения сообщения энтропия уменьшилась и стала равной H2. Тогда количество информации, содержащееся в этом сообщении, равно I = H1 - H2. Если неопределенность в результате получения сообщения снимается полностью, т.е. H2 = 0, то I = H1 или I = Hаприорн. - Hапостериорн..
Энтропия обладает следующими свойствами:
1. Энтропия всегда неотрицательна, т.к. значения вероятностей выражаются числами, не превосходящими единицу, а их логарифмы, следовательно, отрицательными числами, так что члены суммы в формуле (2.3) всегда положительны.
2. Энтропия равна 0 в том и только в том случае, когда вероятность одного из исходов pk = 1, следовательно, вероятность всех остальных исходов равна 0. Это соответствует тому случаю, когда исход опыта может быть предсказан с полной достоверностью и отсутствует всякая неопределенность, сообщение об исходе не несет никакой информации.
3. Энтропия имеет наибольшее значение, когда вероятности всех исходов равны между собой p1 = p2 . . . = pm = 1/m, тогда
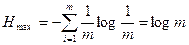 . (2.4.)
. (2.4.)
Если полученное выражение сравнить с (2.1), то это явится еще одним доказательством того, что мера Хартли дает представление о потенциальных возможностях информационной системы. В случае неравенства вероятностей количество информации по Шеннону меньше информационной емкости системы.
Рассмотрим простейший пример с элементарным двоичным событием.
1) пусть p1 = p2 = 0,5, тогда H = -(0,5log0,5 + 0,5log0,5) = 1 бит;
2) пусть p1 = 0,9, p2 = 0,1, тогда H = -(0,9log0,9 + 0,1log0,1) = 0,46 бит;
3) пусть p1 = 1, p2 = 0, тогда H = -(1log1 + 0log0) = 0 бит.
Если во всех полученных выражениях под опытом X понимать способность некоторого дискретного источника формировать то или иное сообщение из их совокупности X, то все сказанное о количестве информации и энтропии может быть отнесено к источнику информации.
Введение понятия энтропии источника позволяет дать точные определения упомянутых во введении характеристик, называемых избыточностью источника и производительностью источника.
Относительная избыточность источника определяется по формуле
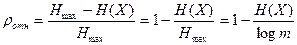 , (2.5)
, (2.5)
где m - объем алфавита источника, т.е. способность формировать m различных сообщений (символов). Относительная избыточность показывает, какая доля максимально возможной при данном объеме алфавита энтропии не используется источником.
Пусть, например, источник выдает символы x1, x2, x3, x4 с вероятностями p(x1)=0,2, p(x2)=0,3, p(x3)=0,4, p(x4)=0,1. Найти количество информации в каждом из символов источника при их независимом выборе (источник без памяти). Требуется найти энтропию и избыточность данного источника.
Количество информации в каждом из символов xi определяется по формуле (2.2)
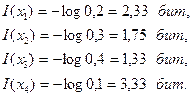
Энтропия источника, выдающего эти символы, находится по формуле (2.3)
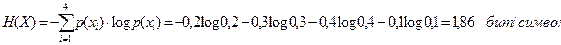 . Избыточность источника находится по формуле (2.5)
. Избыточность источника находится по формуле (2.5) 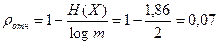 .
.
Избыточность источника зависит как от степени неравновероятности отдельных символов, так и от наличия и протяженности статистических связей между последовательно выбираемыми символами, т.е. от памяти источника.
Если источник без памяти, т.е. последовательно передаваемые символы независимы, и все символы равновероятны, то H(X) = Hmax и rотн = 0.
Источник, как и случайный процесс, называется стационарным, если описывающие его вероятностные характеристики не меняются во времени.
Пусть, например, стационарный источник выдает за время Т=106 секунд 107 бит информации двоичными посылками длительностью t=10 мс. За какое время и каким количеством двоичных посылок можно передать тот же объем информации, если соответствующей обработкой полностью устранить избыточность источника. Определить избыточность источника.
Заданное количество информации I = 107 бит источник передает n посылками или символами, где n = Т/t = 108. Тогда среднее количество информации, приходящееся на одну посылку или символ, H = I/n =0,1 бит/символ. Если в результате соответствующей обработки избыточность полностью устранена, то каждый символ двоичного источника несет в себе Hmax = 1 бит информации. Тогда заданное количество информации может быть передано n0= I/ Hmax = 107 посылками при той же их длительности t=10 мс за время T0 = t n0 =105 c.
Избыточность источника по формуле (2.5) 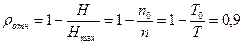 .
.
Если дискретный источник выдает сообщения, затрачивая в среднем время Т на каждое сообщение, то производительностью (в битах в секунду) такого источника называется суммарная энтропия сообщений, переданных в единицу времени
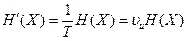 , (2.6)
, (2.6)
где 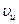 - скорость источника, под которой понимается количество сообщений (символов), выдаваемых источником в единицу времени.
- скорость источника, под которой понимается количество сообщений (символов), выдаваемых источником в единицу времени.
2.3. Энтропия объединения (ансамбля)
Формула (2.3) получена в предположении, что существует неопределенная ситуация X, которая характеризуется вполне определенным набором альтернатив x1, x2, . . . , xm и известными априорными вероятностями этих альтернатив p(x1), p(x2), . . . , p(xm). Таким образом, на множестве (ансамбле) возможных сообщений задается распределение вероятностей, и это позволяет вычислить по формуле (2.3) энтропию источника.
Однако информационный акт в любой информационной системе состоит в передаче сообщения от источника к получателю. В связи с этим возникает необходимость в определении количества информации, содержащегося в одном ансамбле относительно другого.
Для этого рассмотрим объединение двух дискретных ансамблей X и Y, вообще говоря, зависимых друг от друга. Интерпретировать это объединение в зависимости от решаемой задачи можно по-разному: а) как пару ансамблей сообщений, б) как ансамбль сообщений X и ансамбль сигналов Y, с помощью которого эти сообщения передаются, в) как ансамбль сообщений (сигналов) X на входе канала и ансамбль сообщений (сигналов) Y на выходе канала и т.д.
При этом ансамбль Y задается аналогичной ансамблю X схемой
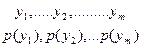 ,
,
а схема объединения ансамблей выглядит следующим образом
x1 x2 . . . xm
y1 p(x1y1) p(x2y1) . . . p(xmy1)
y2 p(x1y2) p(x2y2) . . . p(xmy2)
. . . .
ym p(x1ym) p(x2ym) . . . p(xmym),
где вероятности произведения совместных зависимых событий определяются по формуле 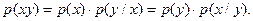
С объединением событий связаны понятия совместной и условной энтропии и взаимной информации.
Совместной энтропией H(XY) называется среднее количество информации на пару сообщений (например, переданного и принятого). По аналогии с теоремой умножения вероятностей (1.7)
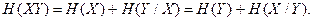 (2.7)
(2.7)
Здесь 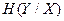 - условная энтропия Y относительно X или мера количества информации в приемнике, если известно, что передается X, а
- условная энтропия Y относительно X или мера количества информации в приемнике, если известно, что передается X, а 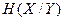 - условная энтропия X относительно Y или мера количества информации об источнике, когда известно, что принимается Y.
- условная энтропия X относительно Y или мера количества информации об источнике, когда известно, что принимается Y.
Для условной энтропии справедливо неравенство 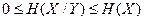 . При этом равенство
. При этом равенство 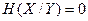 имеет место тогда, когда Y содержит полную информацию об X. Другое равенство
имеет место тогда, когда Y содержит полную информацию об X. Другое равенство 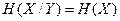 имеет место тогда, когда X и Y независимы, т.е. Y не содержит никакой информации об X.
имеет место тогда, когда X и Y независимы, т.е. Y не содержит никакой информации об X.
Выражения для нахождения условных энтропий через вероятностные схемы ансамблей X и Y и их объединений могут быть получены исходя из следующего.
Пусть на основании статистических данных могут быть установлены вероятности событий y1, y2, . . . , ym при условии, что имело место событие xi. Это будут условные вероятности p(y1/xi), p(y2/xi), . . . , p(ym/xi). Тогда частная условная энтропия будет равна по общему определению энтропии (2.3)
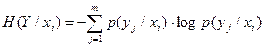 .
.
Далее нужно подсчитать среднее значение H(Y/X) для всех xi при i =1, ..., n, т.е. 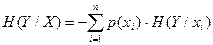 или в развернутом виде
или в развернутом виде
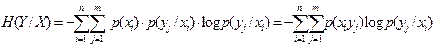 (2.8)
(2.8)
и аналогично
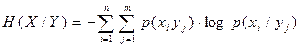 . (2.9)
. (2.9)
В общем случае условная энтропия H(X/Y) меньше H(X) и знание Y снижает в среднем априорную неопределенность X. Из этих соображений целесообразно назвать разность
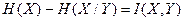 (2.10)
(2.10)
количеством информации, содержащемся в Y относительно X. Эту величину называют взаимной информацией между X и Y.
Взаимная информация измеряется в тех же единицах, что и энтропия, т.е. в битах. Величина I(X,Y) показывает, сколько в среднем бит информации получаем о реализации ансамбля X, наблюдая реализацию ансамбля Y.
Основные свойства взаимной информации:
1. I(X, Y) ³0, причем равенство нулю имеет место тогда и только тогда, когда X и Y независимы друг от друга. (2.11)
2. I(X, Y) = I(Y, X), т.е. Y содержит такое же количество информации об X, какое X содержит относительно Y. (2.12)
3. I(X, Y) £ H(X), причем равенство имеет место тогда, когда по реализации Y можно однозначно восстановить X. (2.13)
4. I(Y, X) £ H(Y), причем равенство имеет место тогда, когда по реализации X можно однозначно восстановить реализацию Y. (2.14)
5. Полагая Y=X и учитывая, что H(X/X) = 0, получим, что I(X,X)=H(X). Это позволяет интерпретировать энтропию источника, как его собственную информацию, т.е. содержащуюся в ансамбле X о самом себе. (2.15)
Все сказанное о безусловной, условной, совместной энтропии и взаимной информации можно свести в табл. 2.1.
Таблица 2.1
| Название | Обозначение | Диаграмма | Соотношения |
| Безусловная энтропия | H(X) | 
| H(X)³ H(X/Y) H(X)= H(X/Y)+ I(X,Y) |
| H(Y) | 
| H(Y)³ H(Y/X) H(Y)= H(Y/X)+ I(X,Y) | |
| Условная энтропия | H(X/Y) | 
| H(X/Y)= H(X) - I(X,Y) |
| H(Y/X) | 
| H(Y/X)= H(Y) - I(X,Y) | |
| Совместная энтропия | H(XY)=H(YX) | 
| H(XY)= H(X)+ H(Y/X)= = H(Y)+ H(X/Y)= = H(X)+ H(Y) - I(X,Y) |
| Взаимная информация | I(X,Y) | 
| I(X,Y)= H(X) - H(X/Y)= = H(Y) - H(Y/X)= = H(XY) - H(X/Y) - H(Y/X) |
Если обозначить T - среднее время передачи одного сообщения, а uк - количество символов, поступающих на вход канала в единицу времени, то величина
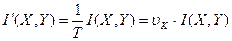 (2.16)
(2.16)
показывает количество информации, приходящееся не на одно сообщение, а на единицу времени и называется скоростью передачи информации от X к Y.
Полученные соотношения позволяют взглянуть на сущность энтропии с другой точки зрения.
Пусть X - ансамбль дискретных сообщений, а Y - ансамбль дискретных сигналов, в которые преобразуются сообщения X. Тогда (2.13, 2.14) I(X, Y) = H(X) в том и только в том случае, когда преобразование X ® Y обратимо. При необратимом преобразовании I(X, Y) < H(X) и разность H(X) - I(X,Y) = H(X/Y) можно назвать потерей информации при преобразовании X ® Y.
Таким образом, информация не теряется только при строго обратимых преобразованиях.
Далее, понимая под X ансамбль сигналов на входе дискретного канала, а под Y - ансамбль сигналов на его выходе, на основании (2.10) можно записать
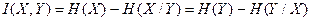 . (2.17)
. (2.17)
Это соотношение можно проиллюстрировать рис. 2.1.
 |
Рис. 2.1
Здесь H(X) - энтропия источника на входе канала, H(Y) - энтропия на выходе канала, H(X/Y) - потери информации в канале, эта величина называется иногда ненадежностью канала, H(Y/X) - посторонняя информация в канале, создаваемая действующими в нем помехами и называемая иногда энтропией шума.Соотношение между H(X/Y) и H(Y/X) определяется свойствами канала. Например, при передаче телефонного сигнала по каналу с узкой полосой частот и низким уровнем помех H(X/Y) >> H(Y/X). Если полоса частот канала достаточна, но сильны наводки от соседнего канала, то H(X/Y) << H(Y/X).
Если в системе нет потерь информации, искажений и помех, то условные энтропии в выражении (2.17) равны нулю, а количество взаимной информации равно энтропии либо источника, либо приемника.
Контрольные
вопросы к
Лекции 10
10-1. Чем характеризуется структурный подход к определению количества информации?
10-2. Как определяется геометрическая мера количества информации при использовании структурного подхода?
10-3. Как определяется комбинаторная мера количества информации при использовании структурного подхода?
10-4. Как определяется аддитивная мера количества информации при использовании структурного подхода?
10-5. Для чего используется семантический подход к определению количества информации?
10-6. Как оценивается содержательность информации при использовании семантического подхода?
10-7. Что служит в качестве меры целесообразности информации при использовании семантического подхода?
10-8. Что служит в качестве меры существенности информации при использовании семантического подхода?
10-9. Чем отличаются подходы Хартли и Шеннона к определению количества информации?
10-10. Что характеризует энтропия?
10-11. Чем отличаются понятия количества информации и энтропии?
10-12. Почему энтропия всегда положительна?
10-13. В каком случае энтропия равна нулю?
10-14. В каком случае энтропия имеет максимальное значение?
10-15. Как определяется относительная избыточность источника?
10-16. В каком случае относительная избыточность источника равна нулю?
10-17. Какой источник информации называется стационарным?
10-18. Что называется производительностью источника информации?
10-19. Что называется совместной энтропией пары сообщений?
10-20. Что называется условной энтропией одного сообщения относительно другого?
10-21. Что называется взаимной информацией между двумя сообщениями?
10-22. В каком случае взаимная информация между двумя сообщениями равна нулю?
10-23. В каком случае взаимная информация между двумя сообщениями равна энтропии одного из сообщений?
10-24. Что называется собственной информацией источника?
10-25. Что называется скоростью передачи информации?
10-26. При каких преобразованиях отсутствуют потери информации?
10-27. Что называется ненадежностью канала?
10-28. Что называется энтропией шума в канале?
Лекция 11
Основная
Теорема
Шеннона
2.4. Основная теорема Шеннона для дискретного канала
Определенную в разделе 2.3 скорость передачи I!(X,Y) от X к Y можно интерпретировать и как скорость передачи информации по дискретному каналу, если под ансамблями X и Y понимать ансамбли сообщений на его входе и выходе
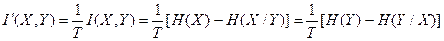 . (2.18)
. (2.18)
Из четырех энтропий, фигурирующих в этом выражении, только H(X) - собственная информация передаваемого сообщения, определяемая источником дискретного сообщения и не зависящая от свойств канала. Остальные три энтропии в общем случае зависят как от источника, так и от канала. Отсюда следует, что такой параметр, как скорость передачи не может характеризовать канал как средство передачи.
Представим, что на вход канала можно подавать сообщения от разных источников, характеризуемых разными распределениями вероятностей p(X). Для каждого такого источника количество информации, передаваемое в канал, будет разным.
Максимальное количество информации, передаваемое в единицу времени, взятое по всем возможным источникам, называется пропускной способностью канала
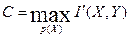 бит/с. (2.19)
бит/с. (2.19)
В качестве примера определим пропускную способность дискретного симметричного канала без памяти, через который в единицу времени передаются u символов из алфавита с объемом m.
Можно записать с учетом (2.18) и (2.19)
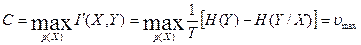 . (2.20)
. (2.20)
Величина H(Y/X) в данном случае легко находится, поскольку условная вероятность p(yj/xi) принимает только два значения
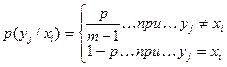 , (2.21)
, (2.21)
где p - вероятность того, что при передаче символа xi будет принят любой другой символ, кроме yj, т.е. вероятность ошибки. Первое из этих значений 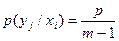 возникает с вероятностью p, а второе - 1-p возникает с вероятностью 1-p. К тому же, поскольку рассматривается канал без памяти, результаты приема отдельных символов независимы. Поэтому в соответствии с полученной ранее формулой (2.8) и с учетом (2.21) можно записать
возникает с вероятностью p, а второе - 1-p возникает с вероятностью 1-p. К тому же, поскольку рассматривается канал без памяти, результаты приема отдельных символов независимы. Поэтому в соответствии с полученной ранее формулой (2.8) и с учетом (2.21) можно записать 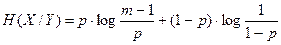 .
.
Следовательно, при этих условиях H(Y/X) не зависит от распределения вероятностей в ансамбле X, а определяется только переходными вероятностями канала.
Таким образом, поскольку в выражении (2.20) только член H(Y) зависит от распределения вероятностей p(X), то максимизировать необходимо именно его.
Максимальное значение H(Y) реализуется тогда, когда все выходные символы yj равновероятны и независимы, а это условие, в свою очередь, выполняется, когда равновероятны и независимы входные символы xi. При этом в соответствии с (2.4) 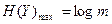 . Отсюда пропускная способность канала в расчете на единицу времени
. Отсюда пропускная способность канала в расчете на единицу времени
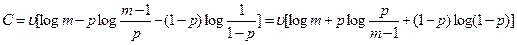 .
.
Для двоичного (m=2) симметричного канала пропускная способность
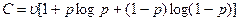 бит/с.
бит/с.
При p=0,5 пропускная способность двоичного канала C=0, поскольку при такой вероятности ошибки последовательность выходных двоичных символов можно получить, совсем не передавая сигналы по каналу (канал не нужен), а просто выбирая их наудачу (например, бросая монету), т.е. при p=0,5 последовательности символов на входе и на выходе канала независимы. То, что пропускная способность при p=0 (канал без шумов) равна пропускной способности при p=1, объясняется тем, что p=1 означает, что все входные символы при прохождении через канал обязательно преобразуются под воздействием помех в противоположные. Следовательно, чтобы правильно восстановить на выходе входное сообщение, достаточно инвертировать все выходные символы.
Пусть, например, по каналу передается сообщение, формируемое из 8 символов xi с вероятностями их появления.
| xi | x1 | x2 | x3 | x4 | x5 | x6 | x7 | x8 |
| pi | 0,20 | 0,15 | 0,20 | 0,15 | 0,10 | 0,10 | 0,05 | 0,05 |
Канал имеет полосу пропускания, позволяющую передавать элементы сообщения со средней длительностью tи = 0,5 мс. Шум в канале отсутствует.
Тогда, поскольку шум отсутствует, энтропия шума H(Y/X) из формулы (2.18) равна нулю. Тогда из этой же формулы 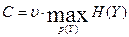 . В соответствии с (2.4)
. В соответствии с (2.4) 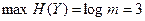 , т.е.
, т.е. 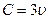 . Канал способен пропускать в единицу времени
. Канал способен пропускать в единицу времени 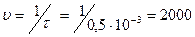 символов. Следовательно С = 3*2000 = 6000 бит/с. Скорость передачи определяется по формуле (2.18)
символов. Следовательно С = 3*2000 = 6000 бит/с. Скорость передачи определяется по формуле (2.18) 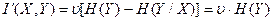 . Величина H(Y) находится по определению энтропии (2.3)
. Величина H(Y) находится по определению энтропии (2.3) 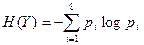 =0,464+0,411+0,464+0,411+0,332+0,332+
=0,464+0,411+0,464+0,411+0,332+0,332+
+0,216+0,216=2,846 бит/символ. Тогда скорость передачи 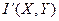 = 2000*2,846 = 5692 бит/с.
= 2000*2,846 = 5692 бит/с.
Пропускная способность канала характеризует потенциальные возможности канала по передаче информации. Они раскрываются в фундаментальной теореме теории информации, известной как основная теорема Шеннона.
Применительно к дискретному источнику и каналу она формулируется так: «Если производительность источника сообщений 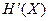 меньше пропускной способностиСканала
меньше пропускной способностиСканала 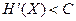 , то существует способ кодирования (преобразования сообщения в сигнал на входе) и декодирования (преобразования сигнала в сообщение на выходе канала), при котором вероятность ошибочного декодирования может быть сколь угодно малой. Если
, то существует способ кодирования (преобразования сообщения в сигнал на входе) и декодирования (преобразования сигнала в сообщение на выходе канала), при котором вероятность ошибочного декодирования может быть сколь угодно малой. Если 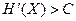 , то таких способов не существует».Таким образом, согласно теореме Шеннона, конечная величина С - это предельное значение скорости безошибочной передачи информации по каналу.
, то таких способов не существует».Таким образом, согласно теореме Шеннона, конечная величина С - это предельное значение скорости безошибочной передачи информации по каналу.
Этот результат оказывается особенно ценным, так как интуиция его не подтверждает. Действительно, очевидно, что при уменьшении скорости передачи информации можно повысить достоверность. Этого можно добиться, например, путем многократного повторения каждой буквы сообщения. Однако для обеспечения нулевой ошибки интуитивно кажется, что скорость передачи должна стремиться к нулю, так как число повторений должно быть бесконечно большим. Теорема же утверждает, что всегда путем выбора подходящего кода можно обеспечить ненулевую скорость передачи.
К сожалению, теорема Шеннона неконструктивна, поскольку она доказывает только существование таких способов кодирования и декодирования, не указывая какого-либо конкретного способа. Тем не менее, значение и фундаментальность теоремы Шеннона трудно переоценить, поскольку она устанавливает пределы достижимого в области кодирования и передачи информации.
Рассмотрим ее содержание более подробно. Как отмечалось ранее, для восстановления по пришедшему сигналу переданного сообщения необходимо, чтобы сигнал содержал о нем информацию, равную энтропии сообщения. Следовательно, для правильной передачи сообщения необходимо, чтобы скорость передачи информации была не меньше производительности источника 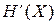 . (2.22)
. (2.22)
Так как по определению скорость передачи информации не превышает значения пропускной способности канала, то неравенство является необходимым условием для точной передачи сообщения. Но является ли оно достаточным? Вопрос сводится к тому, можно ли установить такое соответствие (код) между сообщением X и сигналом Y, чтобы вся информация, полученная на выходе канала о сигнале Y, была в то же время информацией о сообщении X?
Положительный ответ на этот вопрос очевиден в случае, когда в канале нет помех, и сигнал принимается безошибочно. При этом скорость передачи информации по каналу равна производительности кодера 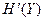 и, если между X и Y установлено однозначное соответствие, то по принятому сигналу можно однозначно восстановить сообщение.
и, если между X и Y установлено однозначное соответствие, то по принятому сигналу можно однозначно восстановить сообщение.
В общем случае в канале имеются помехи, сигнал Y принимается с ошибками, так что скорость передачи информации по каналу меньше производительности кодера . Отсюда с учетом подчеркнутого выше (2.22) утверждения следует, что
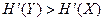 . (2.23)
. (2.23)
Это значит, что производительность кодера, на выходе которого формируется сигнал Y, должна быть выше производительности источника, на выходе которого формируется сообщение X. Следовательно, Y содержит кроме информации об X дополнительную собственную информацию. Часть информации о сигнале Y в канале теряется. Вопрос сводится к следующему: можно ли осуществить кодирование так, чтобы терялась только дополнительная, избыточная часть собственной информации Y, а информация об X сохранялась? Теорема Шеннона дает на этот вопрос почти положительный ответ, с той лишь поправкой, что скорость потери информации не равна в точности нулю, но может быть сделана сколь угодно малой. Соответственно, сколь угодно малой может быть сделана вероятность ошибочного декодирования. При этом, чем меньше допустимая вероятность ошибочного декодирования, тем сложнее должен быть код.
Верхняя граница средней вероятности ошибочного декодирования 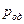 по всем возможным кодам определяется выражением
по всем возможным кодам определяется выражением
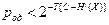 , (2.24)
, (2.24)
где Т - длительность последовательности кодируемых сообщений или длительность последовательности сигналов, соответствующей последовательности сообщений.
Из выражения (2.24) следует, что верность передачи тем выше, чем больше Т, т.е. чем длиннее кодируемый отрезок сообщения, а, следовательно, и больше задержка при приеме информации, и чем менее эффективно используется пропускная способность канала, т.е. чем больше разность 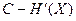 , называемая иногда запасом пропускной способности. Из этого следует также, что существует возможность обмена между верностью, величиной задержки и эффективностью системы. С увеличением Т существенно возрастает сложность кодирования и декодирования (число операций, число элементов и стоимость аппаратуры). Поэтому чаще всего на практике предпочитают иметь умерен
, называемая иногда запасом пропускной способности. Из этого следует также, что существует возможность обмена между верностью, величиной задержки и эффективностью системы. С увеличением Т существенно возрастает сложность кодирования и декодирования (число операций, число элементов и стоимость аппаратуры). Поэтому чаще всего на практике предпочитают иметь умерен
Дата добавления: 2022-02-05; просмотров: 210;
Поиск по сайту
Узнать еще
- CASE-технология создания информационных систем
- II этап. Установка свойств объектов
- III. Биогеохимические циклы элементов и веществ (на примере основных биогенных элементов: углерод, азот, фосфор) и их количественные характеристики.
- III. Единство и взаимосвязь процессов воспитания и обучения.
- III. Организационное обеспечение специальной оценки условий труда.
- Автоматизация деловых процессов
- Автоматизация процессов управления перевозками
- Автоматизация процессов эксплуатации недвижимости

Публикации по технике и механике

Публикации по биологии

Публикации по информатике

Публикации по строительству

Публикации по физике

Публикации по химии

Публикации по электронике

Публикации по искусству

Публикации по географии

Публикации по медицине
