Загальні області пам'яті
Два і більш за процеси можуть використовувати одну і ту ж фізичну область пам'яті. Найпростіше це досягається в тих моделях пам'яті, які забезпечують динамічну трансляцію адрес. Нагадаємо, що кожен процес має власну таблицю сегментів або сторінок, в якій міститься, крім іншого, базова адреса сегменту/сторінки у фізичній пам'яті. Для області пам'яті, що розділяється, створюється по елементу в таблиці для кожного процесу, що її використовує. У чисто сторінковій моделі, проте, виникають труднощі, пов'язані з тим, що область пам'яті, що розділяється, може мати об'єм, некратний розміру сторінки, зазвичай в таких випадках область, що розділяється, вирівнюється до межі сторінки. У сегментній або сегментно-сторінковій моделі таких проблем немає. Оскільки для кожного процесу сегмент, що розділяється, описується своїм дескриптором, права доступу до сегменту можуть бути встановлені різними для різних процесів.
У разі іменованих областей пам'яті один процес створює загальну область пам'яті:
vAddr = createNamedMemorySegment(segmentName, segmentSize);а другий її "відкриває":
vAddr = openNamedMemorySegment(segmentName);У цих викликах segmentName - ім'я області, segmentSize - її розмір. Обидва виклики повертають віртуальну адресу загальної області пам'яті у віртуальному адресному просторі процесу - vAddr.
Для неіменованої області пам'яті створення області здійснюється викликом:
vAddr = createMemorySegment(segmentSize);а "відкриття":
vAddr = openMemorySegment(hostAddr, hostPid);де hostAddr - віртуальна адреса області пам'яті у процесу-творця області, hostPid - ідентифікатор процесу-творця області. Цей виклик повертає віртуальна адреса області в адресному просторі процесу, що відкрив область. Зрозуміло, у складі API є системні виклики "закрытия"/уничтожения загальної області пам'яті.
Області пам'яті, що розділяються, проте, породжують ряд проблем як для програмістів, так і для ОС. Проблеми програмістів - ті, що розглядалися в попередньому розділі: взаємне виключення процесів при доступі до загальної пам'яті. Програмісти можуть диференціювати права доступу для процесів або організувати взаємне виключення, використовуючи семафори (див. нижчий). Проблеми ОС - організація свопінгу. Очевидно, що вірогідність витіснення сегменту, що розділяється, або сторінки повинна бути тим менше, чим більше процесів розділяють цей сегмент/сторінку. Якщо кожен процес має власний дескриптор сегменту, що розділяється, або сторінки, то облік використання сегменту або сторінки (поля used і dirty) вестимуться по кожному процесу окремо. ОС повинна обробляти, наприклад, такий випадок: два процеси - A і B - розділяють сегмент; процес A провів запис в сегмент і в його дескрипторі сегмент помічений, як "брудний". В той час, коли активний процес B, ухвалюється рішення про витіснення цього сегменту з пам'яті. Але в дескрипторі процесу B цей сегмент має ознаку "чистий", тому сегмент може бути звільнений у фізичній пам'яті без збереження на зовнішній пам'яті і зміни в сегменті, зроблені процесом A, будуть загублені. ОС доводиться вести окрему таблицю сегментів, що розділяються, в якій відображати дійсний їх стан.
З погляду ідентифікації області пам'яті, що розділяються, можуть розглядатися як віртуальні комунікаційні порти. Для загальної області може бути за угодою між розробниками взаємодіючих процесів встановлено зовнішнє ім'я, яке буде використано для діставання доступу. (У Windows 95, наприклад, такі області називаються "Файлами пам'яті, що відображається," - memory mapped file - і для встановлення доступу до них використовуються системні виклики типу create і open). Для неіменованих областей пам'яті можлива передача селектора (номери в таблиці дескрипторів) від одного процесу до іншого.
У системах, які орієнтовані на процесор Intel-Pentium, може використовуватися та обставина, що адресація можлива через дві таблиці дескрипторів - LDT і GDT. За рахунок цього загальний адресний простір процесу може досягати 4 Гбайт. З них молодші 2 Гбайт адресуються через LDT а старші - через GDT. Глобальна таблиця дескрипторів - загальна для всіх процесів, і саме вона може використовуватися для доступу до спільно використовуваної пам'яті. Розміщення в загальних віртуальних адресах зручно для системних програм і динамічних бібліотек, до яких відбуваються часті звернення із застосувань: якщо ці компоненти ОС знаходяться в адресному просторі процесу, то звернення до них не вимагають перемикання контексту. Але з іншого боку, це знижує надійність: якщо системні компоненти доступні для застосування, то вони можуть бути їм зіпсовані. Тому така "розкіш" може бути допущена тільки в однопользовательских системах.
Семафори
У попередньому розділі ми достатньо детально розглянули суть і властивості семафорів. ОС може надавати семафори в розпорядження користувача, як засіб для самостійного вирішення завдань, що вимагають взаємного виключення і/або синхронізації.
При роботі з іменованим семафором один з процесів повинен створити системний семафор за допомогою виклику createSemapore, інші процеси дістають доступ до створеного системного семафора за допомогою виклику openSemaphore. Серед вхідних параметрів цих викликів є зовнішнє ім'я семафора, виклики повертають маніпулятор для семафора, використовуваний для його ідентифікації при подальшій роботі з ним. При закінченні роботи з системним семафором процес повинен виконати виклик closeSemaphore. Семафор знищується, коли він закритий у всіх процесах, що його використали.
Виконання операцій над семафором може забезпечуватися системним викликом вигляду:
flag = semaphoreOp(semaphorId, opCode, waitOption);де semaphorId - маніпулятор семафора, opCode - код операції, waitOption - опція очікування, flag - значення, що повертається, ознака успішного виконання операції або код помилки.
Крім основних для семафорів P- і V-операций, конкретні семафорні API ОС можуть включати розширені і сервісні функції, такі як безумовна установка семафора, установка семафора і очікування його очищення, очікування очищення семафора. При виконанні системних викликів - аналогів P-операции, як правило, є можливість задати опцію очікування - блокувати процес, якщо виконання P-операции неможливе, або завершити системний виклик з ознакою помилки.
У багато сучасних ОС разом з семафорами "в чистому виді" API представляє ті ж семафори і у вигляді "прикладних" об'єктів - об'єктів взаємного виключення і подій. Хоча зміст цих об'єктів одне і те ж - семафор, ОС відносно цих об'єктів представляє для прикладних процесів специфічну семантику API, відповідну завданням взаємного виключення і синхронізації.
Всі сучасні ОС надають прикладному процесу можливість працювати з "масивами семафорів", тобто, задавати список семафорів і виконувати операцію над всім списком, наприклад, чекати очищення будь-якого семафора в заданому списку. Найбільш розвинений цей засіб в ОС Unix, де є можливість виконувати за один системний виклик semop (аналог нашого semaphoreOp) відразу декількох різних операцій над декількома семафорами, причому весь список операцій виконується, як одна транзакція. Неіменовані семафори зазвичай використовуються як засіб взаємного виключення і синхронізації роботи ниток одного процесу.
Програмні канали
Програмний канал по-англійськи називається pipe (труба), і це вельми вдала назва. Канал дійсно можна представити як трубопровід пневматичної пошти, прокладений між двома процесами, як показано на рис.9.1. По цьому трубопроводу дані передаються від одного процесу до іншого. Як і трубопровід, програмний канал однонаправлений (хоча, наприклад, в Unix одним системним викликом створюються відразу два різноспрямовані канали). Як і трубопровід, програмний канал має власну ємкість: дані записані в канал, не обов'язково повинні негайно вибиратися не протилежному його кінці, але можуть накопичуватися в каналі, поки це дозволяє його ємкість. Як і трубопровід, канал працює по дисципліні FIFO: перший увійшов - перший вийшов.
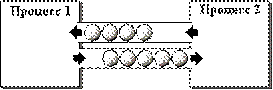 Ріс.9.1. Програмні канали Ріс.9.1. Програмні канали
|
Зі всіх засобів взаємодії між процесами канали (pipe) краще всього вписуються в модель віртуальних комунікаційних портів. Канал для процесу практично аналогічний файлу. Спеціальні системні виклики типу createPipe, openPipe використовуються для створення каналу і діставання доступу до каналу, а для роботи з каналом використовуються ті ж виклики read і write, що і для файлів, і навіть закриття каналу виконується файловим системним викликом close. При створенні каналу для нього створюється дескриптор, як для відкритого файлу, що дозволяє працювати з ним далі, як з файлом. Канал, проте, є не зовнішніми даними, а областю пам'яті. Для каналу виділяється пам'ять в системній області, що може обмежувати ємкість каналу.
Найчастіше використовуються неіменовані канали, як засіб зв'язку між батьком і нащадком. Операція створення неіменованого каналу повертає два файлові маніпулятори: для читання і для запису. Процес-предок передає ці маніпулятори процесу-нащадкові. Якщо зв'язок між предком і нащадком однонаправлений, то кожен з них закриває канал по одному з маніпуляторів. Наприклад, якщо дані передаються тільки від предка до нащадка, то предок після передачі маніпуляторів закриває канал на читання, а нащадок - на запис. Приклад встановлення такого зв'язку в ОС Unix приведений в розділі 11, у фрагменті програми командного інтерпретатора.
З погляду реалізації каналом є класичний варіант завдання "виробник-споживач": один процес пише в канал дані, інший - читає їх з каналу. Якщо при спробі запису даних в канал виявляється, що канал повний, що пише процес блокується до звільнення місця в каналі, якщо при спробі читання даних виявляється, що канал порожній - процес, що читає, блокується до появи в каналі даних. Внутрішнім механізмом ОС, що забезпечує синхронізацію в таких ситуаціях, є, звичайно ж, семафор.
Іменовані канали є зручним засобом клієнт-серверних комунікацій. Іменовані канали в деяких ОС (наприклад, OS/2) істотно відрізняються від неіменованих. Іменовані канали орієнтовані в цих системах перш за все на взаємодію процесів в мережевому середовищі (або, точніше, для них прозоро, чи знаходяться обидва процеси на одному комп'ютері або в різних вузлах мережі). Такий канал двонаправлений, тобто, до нього можливі звернення і для читання, і для запису. Дані в каналі можуть передаватися як потоком байт, так і повідомленнями. У останньому випадку кожне повідомлення забезпечується заголовком, в якому указується його довжина. До одного кінця каналу постійно підключений процес, що його створив, - власник або сервер, до іншого кінця можуть підключатися різні процеси-клієнти, таким чином, обмін даними по іменованому каналу між процесами, жоден з яких не є власником каналу, неможливий. При створенні каналу (системний виклик createNamedPipe) указується максимально можливе число клієнтів, які можуть бути одночасно підключені до каналу (це число, втім, може і не обмежуватися). Коли власник створює канал, канал знаходиться в так званому відключеному стані. Системним викликом connectNamedPipe власник переводить канал в стан, що чекає. Тепер процеси-клієнти можуть підключатися до іншого кінця каналу за допомогою файлових системних викликів openNamedPipe. Канал, відкритий хоч би одним клієнтом, вважається підключеним, сервер і підключені клієнти можуть працювати з ним, використовуючи виклики файлового API. Клієнти відключаються від каналу викликом close, у розпорядженні власника є виклик disconnectNamedPipe - розриву каналу. Крім звичайних викликів файлового обміну, для роботи з іменованим каналом у складі API можуть бути спеціальні системні виклики, що забезпечують виконання складних транзакцій на іменованому каналі наприклад: transactNamedPipe - взаємний обмін даними (вивід і введення) за одну операцію, callNamedPipe - забезпечує також відкриття каналу, взаємний обмін, закриття каналу. Крім того, до іменованого каналу або до декількох іменованих каналів може бути підключений семафор, який скидається при зміні стану каналу (заповнений - не заповнений, порожній - не порожній).
Черги повідомлень
Черги утілюють модель взаємодії процесів "багато відправників - один одержувач". Цю модель часто називають поштовою скринькою (mailbox) із-за схожості з поштовою скринькою, що висить на дверях кожної квартири. Процес-одержувач є власником черги, він створює чергу, а решта процесів дістає до неї доступ, "відкриваючи" її. Черга зазвичай має зовнішнє ім'я. Передача даних в черзі відбувається завжди повідомленнями, причому кожне повідомлення має заголовок і тіло. Заголовок завжди має фіксований для даної системи формат. У нього обов'язково входить довжина повідомлення, а інша інформація залежить від специфікацій конкретної системи: це може бути пріоритет повідомлення, тип повідомлення, ідентифікатор процесу, що послав повідомлення і тому подібне Тіло повідомлення інтерпретується по правилах, що встановлюються самими процесами - відправником і одержувачем. Заголовок і тіло є істотно різними структурами даних і розташовуються в різних місцях в пам'яті. Власне черга (найчастіше - лінійний список) ОС складає із заголовків повідомлень. У елементи черги включаються покажчики на тіла повідомлень, розташовані в пам'яті системи або процесів. Як правило, можливості процесу-одержувача повідомлень не обмежуються читанням по дисципліні FIFO, йому надається багатший вибір дисциплін: LIFO, по пріоритету, по типах, по ідентифікаторах відправника і тому подібне У розпорядженні власника є також засоби визначення розміру черги, а можливо, і проглядання черги - неруйнуючого читання з неї. У розпорядженні процесу-відправника є тільки виклик типу sendMessage - посилки повідомлення в чергу. Якщо при спробі процесу послати повідомлення виявляється, що черга заповнена, процес-відправник блокується. Це, втім, досить окремий випадок, оскільки системні обмеження на розмір черг ніколи не бувають дуже жорсткими. Процес-одержувач блокується при спробі читати повідомлення, коли черга порожня. Істотним питанням при конструюванні механізму черг є питання про включення або невімкнення в ОС системної буферизації повідомлень. При включенні такого засобу (рис.9.2) тіло посиланого повідомлення копіюється в системну область пам'яті, а при читанні - копіюється з неї в адресний простір процесу-одержувача. За відсутності системної буферизації тіла повідомлень зберігаються в загальній для відправника і одержувача пам'яті, а передається тільки покажчик на тіло повідомлення (рис.9.3). У першому випадку виконуються додаткові пересилки, витрачається додаткова пам'ять і вводяться жорсткіші обмеження на об'єм повідомлень, але досягається надійність передачі і значно більш простій інтерфейс процесів. У другому випадку значно економиться пам'ять, але самі процеси повинні піклуватися про управління спільно використовуваною пам'яттю і про збереження повідомлень в ній. За відсутності системної буферизації повідомлень застосовуються зазвичай два методи передачі тіла повідомлення: або процес-відправник поміщає тіло повідомлення в окремий сегмент, що розділяється, отримує у ОС маніпулятор цього сегменту для процесу-одержувача і передає цей маніпулятор у складі повідомлення; або для всіх повідомлень виділяється одна загальна область пам'яті із загальним маніпулятором, і для розміщення повідомлення в нім використовуються системні виклики виділення пам'яті в купі.
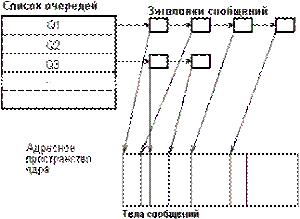 Ріс.9.2. Розміщення повідомлень в адресному просторі ядра Ріс.9.2. Розміщення повідомлень в адресному просторі ядра
|
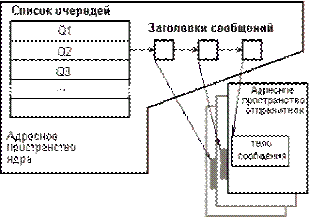 Ріс.9.3. Розміщення повідомлень в адресному просторі процесу-відправника Ріс.9.3. Розміщення повідомлень в адресному просторі процесу-відправника
|
Література
1. Вакал Є.С., Карпенко С.Г., Тригуб О.С. Практикум з операційних систем Windows: метод вказівки. - К., 2004.- 245с.
2. Грайворонський М.В. Операційні системи. Лабораторний практикум. – Київ: КПІ, 2005.- 52с.
3. Олифер В., Олифер Н. Сетевые операционные системы: Учебник для вузов, 2-е изд. – СПб: Питер, 2008. - 672с.
4. Таненбаум Э. С. Современные операционные системы. 2-е изд. – СПб: Питер, 2007. - 1040с.
5. Третяк В.Ф., Голубничий Д.Ю., Кавун С.В. Основи операційних систем. - Х.: Видавництво ХНЕУ, 2005.
6. Харт, Джонсон, М. Системное программирование в среде Win32, :Пер. с англ.: - М.: Издательский дом "Вильямс" , 2001.
7. Системное программное обеспечение./ А.В.Гордеев, А.Ю.Молчанов: - СПб.: Питер, 2001.
8. Соломон Д., Руссинович М. Внутреннее устройство Microsoft Windows 2000. Мастер-класс. /Пер. с англ. – СПб.: Питер; М.: Издательско-торговый дом "Русская редакция", 2001.
9. Негус К. Red Hat Linux 7. Библия пользователя.: пер. с англ. – М.: Издательский дом "Вильямс", 2002.
Дата добавления: 2016-07-27; просмотров: 1186;
Поиск по сайту

Публикации по технике и механике

Публикации по биологии

Публикации по информатике

Публикации по строительству

Публикации по физике

Публикации по химии

Публикации по электронике

Публикации по искусству

Публикации по истории
