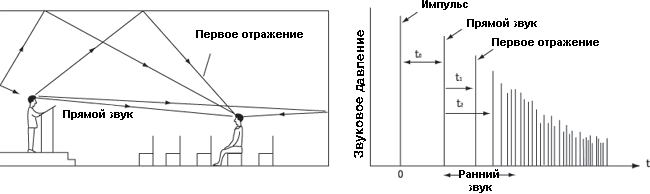
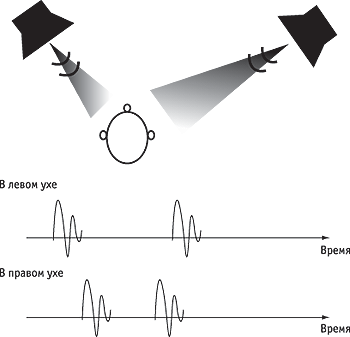
Тембр и общие принципы распознавания слуховых образов
Тембр является идентификатором физического механизма образования звука по ряду признаков, он позволяет выделить источник звука (инструмент или группу инструментов), и определить его физическую природу.
Это отражает общие принципы распознавания слуховых образов, в основе которых, как считает современная психоакустика, лежат принципы гештальт-психологии (geschtalt, нем. - "образ"), которая утверждает, что для разделения и распознавания различной звуковой информации, приходящей к слуховой системе от разных источников в одно и то же время (игра оркестра, разговор многих собеседников и др.) слуховая система (как и зрительная) использует некоторые общие принципы:
- сегрегация - разделение на звуковые потоки, т.е. субъективное выделение определенной группы звуковых источников, например, при музыкальной полифонии слух может отслеживать развитие мелодии у отдельных инструментов;
- подобие - звуки, похожие по тембру, группируются вместе и приписываются одному источнику, например, звуки речи с близкой высотой основного тона и похожим тембром определяются, как принадлежащие одному собеседнику;
- непрерывность - слуховая система может интерполировать звук из единого потока через маскер, например, если в речевой или музыкальный поток вставить короткий отрезок шума, слуховая система может не заметить его, звуковой поток будет продолжать восприниматься как непрерывный;
- "общая судьба" - звуки, которые стартуют и останавливаются, а также изменяются по амплитуде или частоте в определенных пределах синхронно, приписываются одному источнику.
Таким образом, мозг производит группировку поступившей звуковой информации как последовательную, определяя распределение по времени звуковых компонент в рамках одного звукового потока, так и параллельную, выделяя частотные компоненты присутствующие и изменяющиеся одновременно. Кроме того, мозг все время проводит сравнение поступившей звуковой информации с "записанными" в процессе обучения в памяти звуковыми образами.Сравнивая поступившие сочетания звуковых потоков с имеющимися образами, он или легко их идентифицирует, если они совпадают с этими образами, или, в случае неполного совпадения, приписывает им какие-то особые свойства (например, назначает виртуальную высоту тона, как в звучании колоколов).
Во всех этих процессах распознавание тембра играет принципиальную роль, поскольку тембр является механизмом, с помощью которого экстрактируются из физических свойств признаки, определяющие качество звука: они записываются в памяти, сравниваются с уже записанными, и затем идентифицируются в определенных зонах коры головного мозга (Рис. 3).
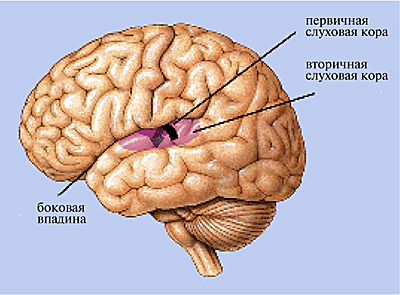
|
| Рис. 3 Слуховые зоны мозга |
Тембр - ощущение многомерное, зависящее от многих физических характеристик сигнала и окружающего пространства. Были проведены работы по шкалированию тембра в метрическом пространстве (шкалы - это различные спектрально-временные характеристики сигнала, см. вторую часть статьи в предыдущем номере). В последние годы, однако, появилось понимание, что классификация звуков в субъективно воспринимаемом пространстве не соответствует обычному ортогональному метрическому пространству, там происходит классификация по "субпространствам", связанным с вышеуказанными принципами, которые и не метрические, и не ортогональные.
Разделяя звуки по этим субпространствам, слуховая система определяет "качество звука", то есть тембр, и решает, к какой категории отнести эти звуки. Однако следует отметить, что все множество субпространств в субъективно воспринимаемом звуковом мире строится на основе информации о двух параметрах звука из внешнего мира - интенсивности и времени, а частота определяется временем прихода одинаковых значений интенсивности. Тот факт, что слух разделяет поступившую звуковую информацию сразу по нескольким субъективным субпространствам, повышает вероятность того, что в каком-то из них она может быть распознана. Именно на выделение этих субъективных субпространств, в которых происходит распознавание тембров и других признаков сигналов, и направлены усилия ученых в настоящее время.
Заключение
Подводя некоторые итоги, можно сказать, что основными физическими признаками, по которым определяется тембр инструмента, и его изменение во времени, являются:
- выстраивание амплитуд обертонов в период атаки;
- изменение фазовых соотношений между обертонами от детерминированных к случайным (в частности, за счет негармоничности обертонов реальных инструментов);
- изменение формы спектральной огибающей во времени во все периоды развития звука: атаки, стационарной части и спада;
- наличие нерегулярностей спектральной огибающей и положение спектрального центроида (максимума спектральной энергии, что связано с восприятием формант) и их изменение во времени (Рис. 4);
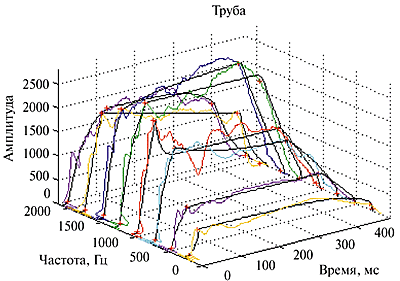
|
| Рис. 4 Общий вид спектральных огибающих и их изменение во времени |
- наличие модуляций - амплитудной (тремоло) и частотной (вибрато);
- изменение формы спектральной огибающей и характера ее изменения во времени;
- изменение интенсивности (громкости) звучания, т.е. характера нелинейности звукового источника;
- наличие дополнительных признаков идентификации инструмента, например, характерный шум смычка, стук клапанов, скрип винтов на рояле и др.
Разумеется, все это не исчерпывает перечень физических признаков сигнала, определяющих его тембр. Поиски в этом направлении продолжаются.
Однако при синтезе музыкальных звуков необходимо учитывать все признаки для создания реалистичного звучания.
Интересная классификация инструментов была предложена в IRCAMe - "бинарное дерево" (рисунок 5). Если выделить пять признаков, и оценить их по 30-бальной шкале (негармоничность, форма атаки, форма спада, вибрато, тремоло, форма огибающей и др.), то все пять исследуемых инструментов можно расположить на "бинарном дереве", что может соответствовать их классификации по тембрам.
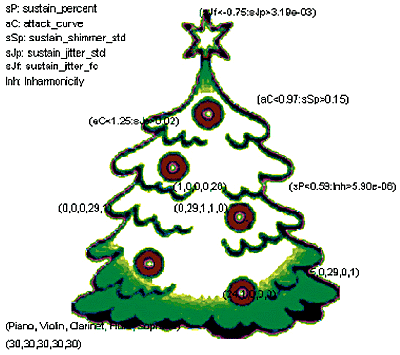
|
| Рис. 5 "Бинарное дерево" |
Приведенные в этих трех статьях сведения являются только несколькими первыми шагами в этом направлении, и далеко не исчерпывают проблемы. Надеюсь, что у нас будет возможность возвращаться к этим проблемам в дальнейшем, а также, надеюсь, что поставленные здесь вопросы заинтересуют наших читателей, и подтолкнут их к проведению научных и практических исследований в направлении анализа и восприятия тембра.
Приложение
Вербальное (словесное) описание тембра
Если для оценки высоты звуков имеются соответствующие единицы измерения: психофизические (мелы), музыкальные (октавы, тоны, полутоны, центы); есть единицы для громкости (соны, фоны), то для тембров такие шкалы построить невозможно, поскольку это понятие многомерное. Поэтому, наряду с описанными выше поисками корреляции восприятия тембра с объективными параметрами звука, для характеристики тембров музыкальных инструментов пользуются словесными описаниями, подобранными по признакам противоположности: яркий - тусклый, резкий - мягкий и др.
В научной литературе имеется большое количество понятий, связанных с оценкой тембров звука. Например, анализ терминов, принятых в современной технической литературе, позволил выявить наиболее часто встречающиеся термины, показанные в таблице. Были сделаны попытки выявить самые значимые среди них, и провести шкалирование тембра по противоположным признакам, а также связать словесное описание тембров с некоторыми акустическими параметрами (см. таблицу 6 в первой части этой статьи, "Звукорежиссер" 2/2001).
| Таблица Основные субъективные термины для описания тембра, используемые в современной международной технической литературе (статистический анализ 30 книг и журналов) Acidlike - кислый | forceful - усиленный | muffled - заглушенный | sober - трезвый (рассудительный) |
| antique - старинный | frosty - морозный | mushy - пористый | soft - мягкий |
| arching - выпуклый | full - полный | mysterious - загадочный | solemn - торжественный |
| articulate - разборчивый | fuzzy - пушистый | nasal - носовой | solid - твердый |
| austere - суровый | gauzy - тонкий | neat - аккуратный | somber - мрачный |
| bite, biting - кусачий | gentle - нежный | neutral - нейтральный | sonorous - звучный |
| bland - вкрадчивый | ghostlike - призрачный | noble - благородный | steely - стальной |
| blaring - ревущий | glassy - стеклянный | nondescript - неописуемый | strained - натянутый |
| bleating - блеющий | glittering - блестящий | nostalgic - ностальгический | strident - скрипучий |
| breathy - дыхательный | gloomy - унылый | ominous - зловещий | stringent - стесненный |
| bright - яркий | grainy - зернистый | ordinary - ординарный | strong - сильный |
| brilliant - блестящий | grating - скрипучий | pale - бледный | stuffy - душный |
| brittle - подвижный | grave - серьезный | passionate - страстный | subdued - смягченный |
| buzzy - жужжащий | growly - рычащий | penetrating - проникающий | sultry - знойный |
| calm - спокойный | hard - жесткий | piercing - пронзительный | sweet - сладкий |
| carrying - полетный | harsh - грубый | pinched - ограниченный | tangy - запутанный |
| centered - концентрированный | haunting - преследующий | placid - безмятежный | tart - кислый |
| clangorous - звенящий | hazy - смутный | plaintive - заунывный | tearing - неистовый |
| clear, clarity - ясный | hearty - искренний | ponderous - увесистый | tender - нежный |
| cloudy - туманный | heavy - тяжелый | powerful - мощный | tense - напряженный |
| coarse - грубый | heroic - героический | prominent - выдающийся | thick - толстый |
| cold - холодный | hoarse - хриплый | pungent - едкий | thin - тонкий |
| colorful - красочный | hollow - пустой | pure - чистый | threatening - угрожающий |
| colorless - бесцветный | honking - гудящий (автомобильный гудок) | radiant - сияющий | throaty - хриплый |
| cool - прохладный | hooty - гудящий | raspy - дребезжащий | tragic - трагичный |
| crackling - трескучий | husky - сиплый | rattling - грохочущий | tranquil - успокаивающий |
| crashing - ломаный | incandescence - накаленный | reedy - пронзительный | transparent - прозразный |
| creamy - сливочный | incisive - резкий | refined - рафинированый | triumphant - торжествующий |
| crystalline - кристаллический | inexpressive - невыразительный | remote - удаленный | tubby - бочкообразный |
| cutting - резкий | intense - интенсивный | rich - богатый | turbid - мутный |
| dark - темный | introspective - углубленный | ringing - звенящий | turgid - высокопарный |
| deep - глубокий | joyous - радостный | robust - грубый | unfocussed - несфокусированный |
| delicate - деликатный | languishing - печальный | rough - терпкий | unobtrsuive - скромный |
| dense - плотный | light - светлый | rounded - круглый | veiled - завуалированный |
| diffuse - рассеяный | limpid - прозрачный | sandy - песочный | velvety - бархатистый |
| dismal - отдаленный | liquid - водянистый | savage - дикий | vibrant - вибрирующий |
| distant - отчетливый | loud - громкий | screamy - кричащий | vital - жизненный |
| dreamy - мечтательный | luminous - блестящий | sere - сухой | voluptuous - пышный(роскошный) |
| dry - сухой | lush (luscious) - сочный | serene, serenity - спокойный | wan - тусклый |
| dull - скучный | lyrical - лирический | shadowy - затененный | warm - теплый |
| earnest - серьезный | massive - массивный | sharp - резкий | watery - водянистый |
| ecstatic - экстатический | meditative - созерцательный | shimmer - дрожащий | weak - слабый |
| ethereal - эфирный | melancholy - меланхоличный | shouting - кричащий | weighty - тяжеловесный |
| exotic - экзотический | mellow - мягкий | shrill - пронзительный | white - белый |
| expressive - выразительный | melodious - мелодичный | silky - шелковистый | windy - ветряный |
| fat - жирный | menacing - угрожающий | silvery - серебристый | wispy - тонкий |
| fierce - жесткий | metallic - металлический | singing - певучий | woody - деревянный |
| flabby - дряблый | мisty - неясный | sinister - зловещий | yearning - тоскливый |
| focussed - сфокусированный | mournful - траурный | slack - расхлябанный | |
| forboding - отталкивающий | muddy - грязный | smooth - гладкий |
Однако, главная проблема состоит в том, что нет однозначного понимания различных субъективных терминов, описывающих тембр. Приведенный в таблице перевод далеко не всегда соответствует тому техническому смыслу, которое вкладывается в каждое слово при описании различных аспектов оценки тембра.
В нашей литературе раньше был стандарт на основные термины, но сейчас дела обстоят совсем печально, поскольку не ведется работа по созданию соответствующей русскоязычной терминологии, и употребляется много терминов в разных, иногда прямо противоположных, значениях.
В связи с этим AES при разработке серии стандартов по субъективным оценкам качества аудиоаппаратуры, систем звукозаписи и др. начал приводить определения субъективных терминов в приложениях к стандартам, а так как стандарты создаются в рабочих группах, включающих ведущих специалистов разных стран, то эта очень важная процедура приводит к согласованному пониманию основных терминов для описания тембров.
В качестве примера приведу стандарт AES-20-96 - "Рекомендации для субъективной оценки громкоговорителей", - где дано согласованное определение таких терминов, как "открытость", "прозрачность", "ясность", "напряженность", "резкость" и др.
Если эта работа будет систематически продолжаться, то, возможно, основные термины для словесного описания тембров звуков различных инструментов и других звуковых источников будут иметь согласованные определения, и будут однозначно или достаточно близко пониматься специалистами разных стран. Мы постараемся информировать об этом наших читателей.
|