Методы сжатия информации.
Характерной особенностью файлов, содержащих графическую информацию является наличие групп повторяющихся пикселей. Следовательно логично было бы использовать для записи таких групп счётчики повторений. Запись состоит из двух частей:
1) Указывается сколько раз нужно повторить следующую запись.
2) Содержится описание какой либо точки.
На основе таких способов записи основаны два стандартных способа уплотнения: RLE4 и RLE8. Они входят как бы составной частью в большинство форматов хранения графики. В способе RLE8 на одну точку отводится полный байт. Также полный байт отводится на то, чтобы записать число повторений.
7 0 7 0

Пример. 03 08 следует читать 08 08 08.
Если в первом старшем байте 0, то следовательно, одна взятая точка.
Пример. 08 02 06 следует читать 00 08 00 02 00 06
Применяют искусственный приём, который позволяет сократить длину записи. Один байт разбивается на две части (логически). Физически запись занимает два байта:

Пример. 00 03 08 02 06. У нас три неповторяющиеся точки – 08 02 06.
Кусочек 00 выделен для организации служебных команд.
Если у нас 0000, то конец строки, если 0001, то конец битовой карты, если 0002, то далее идут два байта, в которых записано смещения по x и y (то есть можно пропускать ряд строк). Если запись начинается не на 00, то это значит, что далее цвета повторяются.
RLE8 более распространён, чем RLE4. В алгоритме RLE4 на описание цвета точки отводится половина байта, то есть четыре разряда. Точки для повторений записываются парами. Первой всегда выводится точка, которая закодирована в старшей половине байта, второй – в младшей половине байта.

 Пусть у нас есть запись: 03 1F ® 01 0F 01 0F 01 0F.
Пусть у нас есть запись: 03 1F ® 01 0F 01 0F 01 0F.
точка точка с цветом 0F
с цветом 01
Если первый байт равен 0, то записываются неповторяющиеся точки. Просматривается второй байт. Там могут находиться записи 00; 01; 02. Тогда это служебные записи. Если это другие комбинации, то в ней указывается число неповторяющихся точек. Обозначим её через n, тогда далее следует n байт, в которых содержится описание точек 2*n. RLE4 используется для изображений с небольшим количеством цветов. Если число цветов такого, что под него достаточно отвести половину байта, RLE8 используется для изображений с большим количеством цветов. В некоторых форматах счётчик повторений организован иначе.
Например, в формате PCX.
7 6 5 0 7 0

служебная зона
В служебной зоне могут быть или 00, или 11. Данные с уплотнением – это 11, а без уплотнения – это 00. Счётчик занимает 6 разрядов и далее следует шаблон повторений.
Ограничения: следует ограничивать число, которое может быть записано в счётчик. Граница C0 – максимум.
Достоинства:
– Простота и приближённость к естественному расположению точек.
Недостатки:
– Если количество повторяющихся точек больше счётчика, то запись надо делать два раза.
– Сжатая последовательность никогда не уходит на следующую строку.
– В тех случаях, когда количество повторяющихся пикселей невелико, то применение такого сжатия
может даже вызвать увеличение объёма файла.
Вообще степень сжатия зависит от конкретной картинки и может достигать в отдельных случаях до 90%.
Метод Хаффмана.
Первоначально он был разработан для кодирования текстовых файлов. Для изображений, которые имеют большую долю основного цвета также бывает очень эффективным.
Основан он на использовании некоторых предварительно вычисленных статистических данных. Предварительно вычисляется статистическая информация для данных и такая же для устойчивых сочетаний у данных. Пусть у нас есть последовательность:
abbbcccddeeeeeeeee f
1 3 3 2 9 1
На основе этой последовательности строится граф. Его начинают строить с тех данных, которые встречаются в последовательности реже всего.
 | 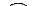 |
0 
 1
1
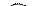 | |||
 | |||


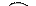 0 0 1
0 0 1
1
0 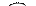 0
0
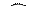
0 1
Те данные, которые встречаются чаще всего будут иметь короткие коды:
е.: 1
b: 010
c: 011
d: 001
a: 0000
f: 0001
Таким образом, мы заменяем данные некоторым двоичным кодом, который тем короче, чем чаще встречаются данные. Эффективность метода зависит от ряда причин:
1. Опирается на предварительную статистику.
2. Степень сжатия зависит от правильного определения статистики.
3. Следует строить граф для определения кодировки. Так как граф можно построить несколькими методами, то минимизация будет разной, то есть сам граф влияет на коды.
Эффективность от вида текста зависит крайне существенно. Существует ограниченный набор задач, где мы получаем нужный эффект. Одна из областей применения – это криптография. Оказывается, что в каждом языке, вероятность, что попадётся данная буква строго фиксируется, и если мы имеем кусок шифрованного текста, то можно вычислить вероятность каждого знака и по таблице расшифровать его.
Дата добавления: 2016-07-27; просмотров: 1394;
Поиск по сайту
Узнать еще
- I. История открытия и методы исследования вирусов
- II. Категории и методы политологии.
- III. Методы искусственной физико-химической детоксикации.
- Абсолютный возраст горных пород и методы его определения
- Автоматические методы изготовления фотошаблонов.
- Агротехнические методы (приемы) обработки почвы.
- Адиабатная работа сжатия воздуха в ступени.
- Административные методы управления природопользованием

Публикации по технике и механике

Публикации по биологии

Публикации по информатике

Публикации по строительству

Публикации по физике

Публикации по химии

Публикации по электронике

Публикации по искусству

Публикации по истории
