Файлова система HPFS.
Скорочення HPFS розшифровується як «High Performance File System» — високопродуктивна файлова система. HPFS уперше з'явилася в OS/2 1.2 і LAN Manager. HPFS була розроблена спільними зусиллями кращих фахівців компанії IBM і Microsoft на основі досвіду IBM по створенню файлових систем MVS, VM/CMS і віртуального методу доступу. Архітектура HPFS-початку створюватися як файлова система, що зможе використовувати переваги багатозадачного режиму і забезпечить у майбутньому більш ефективну і надійну роботу з файлами на дисках великого обсягу.
HPFS була першою файловою системою для ПК, у якій була реалізована підтримка довгих імен. HPFS, як FAT і багато інших файлових систем, має структуру каталогів, але в ній також передбачені автоматичне сортування каталогів і спеціальних розширених атрибутів, що спрощують реалізацію безпеки файлового рівня і створення множинних імен. HPFS підтримує ті ж самі атрибути, що і файлова система FAT, по історичних причинах, але також підтримує і нову форму file-associated, тобто інформацію, так звану розширеними атрибутами (EAs). Кожен ЕА концептуально подібний змінній оточення. Але самою головною відмінністю все-таки є базові принципи збереження інформації про місце розташування файлів.
Принципи розміщення файлів на диску, покладені в основу HPFS, збільшують як продуктивність файлової системи, так і її надійність і відмовостійкість. Для досягнення цих цілей запропоновано кілька способів: розміщення каталогів у середині дискового простору, використання методів бінарних збалансованих дерев для прискорення пошуку інформації про файл, розосередження інформації про місце розташування записів файлів по всьому диску, при тім що записи кожного конкретного файлу розміщаються (по можливості) у суміжних секторах і поблизу від даних про їхнє місце розташування. Дійсно, система HPFS прагне, насамперед, до того, щоб розташувати файл у суміжних кластерах, чи, якщо такої можливості немає, розмістити його на диску таким чином, щоб екстенти (фрагменти, фрагменти файлу, що розташовуються в суміжних секторах диска. Файл має принаймні один екстент, якщо він не фрагментований, а в противному випадку декілька екстентів) файлу фізично були якнайближче один до одного. Такий підхід істотно зменшує час позиціювання голівок запису/читання жорсткого диска і час чекання (rotational latency — затримка між установкою голівки читання/запису на потрібну доріжку диска і початком читання даних з диска). Можна сказати, що файлова система HPFS має, у порівнянні з FAT, що випливають основні переваги:
· висока продуктивність;
· надійність;
· робота з розширеними атрибутами, що дозволяє керувати доступом до файлів і каталогів;
· ефективне використання дискового простору.
Усі ці переваги обумовлені структурою диска HPFS. Розглянемо її більш докладно (мал. 4.10).
 Рис. 4.10. Структура розділу HPFS
Рис. 4.10. Структура розділу HPFS
На початку диска розташовано кілька керуючих блоків. Весь інший дисковий простір у HPFS розбито на частини («смуги», «стрічки» із суміжних секторів, в оригіналі — band). Кожна така група даних займає на диску простір у 8 Мбайт і має свою власну бітову карту розподілу секторів. Ці бітові карти показують, які сектори даної смуги зайняті, а які — вільні. Кожному сектору стрічки даних відповідає один біт у її бітовій карті. Якщо біт має значення 1, то відповідний сектор зайнятий, а якщо 0 — вільний.
Бітові карти двох смуг розташовуються на диску поруч, так само розташовуються і самі смуги. Тобто послідовність смуг і карт виглядає в такий спосіб: бітова карта, бітова карта, стрічка з даними, стрічка з даними, бітова карта, бітова карта і т.д. Таке розташування «стрічок» дозволяє безупинно розмістити на жорсткому диску файл розміром до 16 Мбайт і в той же час не видаляти від самих файлів інформацію про їхнє місцезнаходження. Це ілюструється мал. 10.10.
Очевидно, що якби на весь диск була тільки одна бітова карта, як це зроблено в FAT, то для роботи з нею приходилося б переміщати голівки читання/запису в середньому через половину диска. Саме для того, щоб уникнути цих втрат, у HPFS і розбитий диск на «смуги». Виходить свого роду розподілена структура даних про використовувані і вільні блоки.
Дисковий простір у HPFS виділяється не кластерами, як в FAT, а блоками. У сучасній реалізації розмір блоку взятий рівним розміру одного сектору, але в принципі він міг би бути й іншого розміру. По суті діла, блок – це і є кластер. Розміщення файлів у таких невеликих блоках дозволяє більш ефективно використовувати простір диска, тому що непродуктивні втрати вільного місця складають у середньому всього 256 байт на кожен файл. Згадайте, що чим більше розмір кластера, тим більше місця на диску витрачається дарма. Наприклад, кластер на відформатованому під FAT диску обсягом від 512 до 1024 Мбайт має розмір 16 Кбайт. Отже, непродуктивні втрати вільного простору на такому розділі в середньому складають 8 Кбайт (8192 байт)на один файл, у той час як на розділі HPFS ці втрати завжди будуть складати всього 256 байт на файл. Таким чином, на кожен файл заощаджується майже 8 Кбайт.
На мал. 10.10 показано, що крім «стрічок» із записами файлів і бітових карт у томі з HPFS є ще три інформаційні структури. Це так званий завантажувальний блок (boot block), додатковий блок (super block) і запасний (резервний) блок (spare block). Завантажувальний блок (boot block) розташований у секторах з 0 по 15; він містить ім'я тому, його серійний номер, блок параметрів BIOS і програму початкового завантаження. Програма початкового завантаження знаходить файл OS2LDR, зчитує його в пам'ять і передає керування цій програмі завантаження ОС, що, у свою чергу, завантажує з диска в пам'ять ядро OS/2 - OS2KRNL. І вже OS2KRNL за допомогою зведень з файлу CONFIG.SYS завантажує в пам'ять всі інші необхідні програмні модулі і блоки даних.
У блоці (super block) міститься покажчик на список бітових карт (bitmap bloc; list). У цьому списку перераховані всі блоки на диску, у яких розташовані бітові карти, використовувані для виявлення вільних секторів. Також у додатковому блоці зберігається покажчик на список дефектних блоків (bad bloc list), покажчик на групу каталогів (directory b and), покажчик на файловий вузол (F-node) кореневого каталогу, а також дата останньої перевірки розділу програмою CHKDSK. У списку дефектних блоків перераховані всі ушкоджені сектори (блоки) диска. Коли система виявляє ушкоджений блок, він вноситься в цей список і для збереження інформації більше не використовується. Крім цього в структурі super block міститься інформація про розмір «смуги». Нагадаємо, що в поточній реалізації HPFS розмір «смуги» узятий рівним 8 Мбайт. Блок super block розміщається в секторі з номером 16 логічного диска, на якому встановлена файлова система HPFS.
Резервний блок (spare block) містить покажчик на карту аварійного заміщення (hotfix map чи hotfix-areas), покажчик на список вільних запасних блоків (directory emergency free block list), використовуваних для операцій на майже переповненому диску, і ряд системних прапорів і дескрипторів. Цей блок розміщається в 17 секторі диска. Резервний блок забезпечує високу відмовостійкість файлової системи HPFS і дозволяє відновлювати ушкоджені дані на диску.
Файли і каталоги в HPFS базуються на фундаментальному об'єкті, називаному F-Node. Ця структура характерна для HPFS і аналога у файловій системі FAT не має. Кожен файл і каталог диска має свій файловий вузол F-Node. Кожен об'єкт F-Node займає один сектор і завжди розташовується поблизу від свого файлу чи каталогу (звичайно — безпосередньо перед файлом чи каталогом). Об'єкт F-Node містить довжину і перші 15 символів імені файлу, спеціальну службову інформацію, статистику по доступі до файлу, розширені атрибути файлу і список прав доступу (чи тільки частина цього списку, якщо він дуже великий), асоціативну інформацію про розташування і підпорядкування файлу і т.д. Структура розподілу в F-node може приймати кілька форм у залежності від розміру каталогу чи файлів. HPFS переглядає файл як сукупність одного чи більше секторів. З прикладної програми це не видно; файл поновляється як безупинний потік байтів. Якщо розширені атрибути занадто великі для файлового вузла, то в нього записується покажчик на них.
Скорочене ім'я файлу (у форматі 8.3) використовується, коли файл із довгим ім'ям копіюється чи переміщається на диск із системою FAT, що не допускає подібних імен. Скорочене ім'я утвориться з перших 8 символів оригінального імені файлу, крапки і перших трьох символів розширення імені, якщо розширення є. Якщо в імені файлу присутні кілька крапок, що не суперечить правилам іменування файлів у HPFS, то для розширення скороченого імені використовуються три символи після самої останньої з цих крапок.
Тому що HPFS при розміщенні файлу на диску прагне уникнути його фрагментації, то структура інформації, що міститься у файловому вузлі, досить проста. Якщо файл безупинний, то його розміщення на диску описується двома 32-бітними числами. Перше число являє собою покажчик на перший блок файлу, а друге — довжину екстента, тобто число йдучих один за одним блоків, що належать файлу. Якщо файл фрагментований, то розміщення його екстентів описується у файловому вузлі додатковими парами 32-бітних чисел. Фрагментація відбувається, коли на диску немає неперервної вільної ділянки, досить великої, щоб розмістити файл цілком. У цьому випадку файл приходиться розбивати на декілька екстентів і розташовувати їх на диску роздільно. Файлова система HPFS намагається розмістити екстенти фрагментованого файлу якнайближче один до одного, щоб скоротити час позиціювання голівок читання/запису жорсткого диска. Для цього HPFS використовує статистику, а також старається умовно резервувати хоча б 4 кілобайти місця наприкінці файлів, що ростуть. Ще один спосіб зменшення фрагментування файлів — це розташування файлів, що ростуть назустріч один одному, чи файлів, відкритих різними тредами чи процесами, у різних смугах диска.
У файловомуому вузлі можна розмістити інформацію максимум про вісім екстентів файлу. Якщо файл має більше екстентів, то в його файловий вузол записується покажчик на блок розміщення (allocation block), що може містити до 40 покажчиків на екстенти чи, за аналогією з блоком дерева каталогів, на інші блоки розміщення. Таким чином, дворівнева структура блоків розміщення може зберігати інформацію про 480 сектори, що дозволяє працювати з файлами розміром до 7,68Гбайт. На практиці розмір файлу не може перевищувати 2 Гбайт, але це обумовлено поточною реалізацією інтерфейсу прикладного програмування.
«Смуга», що знаходиться в центрі диска, використовується для збереження каталогів. Ця смуга називається directory band. Як і всі інші «смуги», вона має розмір 8 Мбайт. Однак, якщо вона буде цілком заповнена, HPFS починає розташовувати каталоги файлів в інших смугах. Розташування цієї інформаційної структури в середині диска значно скорочує середній час позиціювання голівок читання/запису. Дійсно, для переміщення голівок читання/запису з довільного місця диска в його центр потрібно в два рази менше часу, чим для переміщення до краю диска, де знаходиться кореневий каталог у випадку файлової системи FAT. Уже тільки одне це забезпечує більш високу продуктивність файлової системи HPFS у порівнянні з FAT. Аналогічне зауваження справедливе і для NTFS, що теж розташовує свій master file table на початку дискового простору, а не в його середині.
Однак істотно більший (у порівнянні з розміщенням Directory Band у середині логічного диска) внесок у продуктивність HPFS дає використання методу збалансованих двійкових дерев для збереження і пошуку інформації про місцезнаходження файлів. Як відомо, у файловій системі FAT каталог має лінійну структуру, спеціальним чином не упорядковану, тому при пошуку файлу потрібно послідовно переглядати його із самого початку. У HPFS структура каталогу являє собою збалансоване дерево з записами, розташованими за абеткою (мал. 4.11). Кожен запис, що входить до складу В-Тгее дерева, містить атрибути файлу, покажчик на відповідний файловий вузол, інформацію про час і дату створення файлу, часу і даті останнього відновлення і звертання, довжині даних, що містять розширені атрибути, лічильник звертань до файлу, довжині імені файлу і саме ім'я, і іншу інформацію.
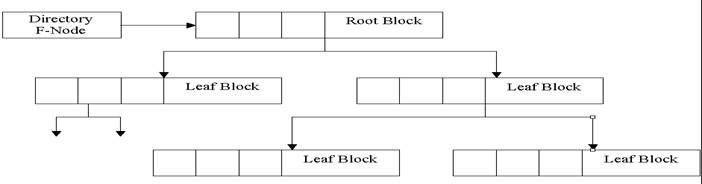
Рис. 4.11. Збалансоване двійкове дерево.
Файлова система HPFS при пошуку файлу в каталозі переглядає тільки необхідні вітки двійкового дерева (B-Tree). Такий метод у багато разів ефективніший, ніж послідовне читання всіх записів у каталозі, що є в системі FAT. Для того щоб знайти шуканий файл у каталозі (точніше, покажчик на його інформаційну структуру F-node), організованому на принципах збалансованих двійкових дерев, більшість записів взагалі читати не потрібно. У результаті для пошуку інформації про файл необхідно виконати істотно меншу кількість операцій читання диска.
Дійсно, якщо, наприклад, каталог містить 4096 файлів, то файлова система FAT зажадає читання в середньому 64 секторів для пошуку потрібного файлу усередині такого каталогу, у той час як HPFS здійснить читання усього тільки 2-4 секторів (у середньому) і знайде шуканий файл. Нескладні розрахунки дозволяють побачити явні переваги HPFS над FAT. Так, наприклад, при використанні 40 входів на блок блоки каталогу дерева з двома рівнями можуть містити 1640 входів, а каталогу дерева з трьома рівнями — вже 65 640 входів. Другими словами, деякий файл може бути знайдений у типовому каталозі з 65 640 файлів максимум за три звертання. Це набагато краще файлової системи FAT, де для пошуку файлу потрібно прочитати в гіршому випадку більш 4000 секторів.
Розмір кожного з блоків, у термінах яких виділяються каталоги в поточній реалізації HPFS, дорівнює 2 Кбайт. Розмір запису, що описує файл, залежить від розміру імені файлу. Якщо ім'я займає 13 байтів (для формату 8.3), то блок з 2 Кбайт вміщає до 40 описувачів файлів. Блоки зв'язані один з одним за допомогою спискової структури (як і описувачі екстентів) для полегшення послідовного обходу.
При перейменуванні файлів може виникнути так зване перебалансування дерева. Створення файлу, перейменування чи стирання може приводити до каскадування блоків каталогів. Фактично, перейменування може зазнати невдачі через недолік дискового простору, навіть якщо файл безпосередньо в розмірах не збільшився. Щоб уникнути цього «нещастя» HPFS підтримує невеликий пул вільних блоків, що можуть використовуватися при «аварії». Ця операція може зажадати виділення додаткових блоків на заповненому диску. Покажчик на цей пул вільних блоків зберігається в SpareBlock.
Важливе значення для підвищення швидкості роботи з файлами має зменшення їхньої фрагментації. У HPFS вважається, що файл є фрагментованим якщо він містить більше одного екстента. Зниження фрагментації файлів скорочує час позиціювання і час чекання за рахунок зменшення кількості переміщень голівок, необхідного для доступу до даних файлу. Алгоритми роботи файлової системи HPFS працюють таким чином, щоб по можливості розміщати файли в послідовних суміжних секторах диска, що забезпечує максимально швидкий доступ до даних згодом. У системі FAT, навпаки, запис наступної порції даних у перший же вільний кластер неминуче приводить до фрагментації файлів. HPFS теж, якщо це є можливим, записує дані і суміжні сектори диска (але не в перший попавший). Це дозволяє трохи знизити число переміщень голівок читання/запису від доріжки до доріжки. При цьому, коли дані дописуються в існуючий файл, HPFS відразу ж резервує як мінімум 4 Кбайт неперервного простору на диску. Якщо ж частина цього простору не знадобилася, то після закриття файлу вона звільняється для подальшого використання. Файлова система HPFS рівномірно розміщає неперервні файли по всьому диску для того, щоб згодом без фрагментації забезпечити їхнє можливе збільшення. Якщо ж файл не може бути збільшений без порушення його неперервності, HPFS знов-таки резервує 4 Кбайт суміжних блоків якнайближче до основної частини файлу з метою скоротити час позиціювання голівок читання/запису і час чекання відповідного сектора.
Очевидно, що ступінь фрагментації файлів на диску залежить як від числа файлів, розташованих на ньому, їхніх розмірів і розмірів самого диска, так і від характеру й інтенсивності самих дискових операцій. Незначна фрагментація файлів практично не позначається на швидкодії операцій з файлами Файли, що складаються з двох-трьох екстентів, практично не знижують продуктивність HPFS, тому що ця файлова система стежить за тим, щоб області даних, приналежні тому самому файлу, розташовувалися якнайближче один від одного. Файл із трьох екстентів має тільки два порушення неперервності і, отже, для його читання буде потрібно всього лише два невеликих переміщення голівки диска. Програми (утиліти) дефрагментації, що є для цієї файлової системи, за замовчуванням вважають наявність двох-трьох екстентів у файлі нормою. Наприклад, програма HPFSOPT з набору утиліт Gamma Tech за замовчуванням не дефрагментує файли, що складаються з трьох і менше екстентів, а файли, що мають більшу кількість екстентів, приводяться до 2 чи 3 екстентам, якщо це можливо (файли обсягом у кілька десятків мегабайт завжди будуть фрагментовані, тому що максимально можливий розмір екстента, як ви пам‘ятаєте, дорівнює 8 Мбайт). Треба сказати, що практика показує що в середньому на диску є не більш 2 відсотків файлів, що мають три і 6ільше екстентів. Навіть загальна кількість фрагментованих файлів, як правило, не перевищує 3 відсотків. Така незначна фрагментація робить досить малий вплив на загальну продуктивність системи.
Тепер коротко розглянемо питання надійності збереження даних у HPFS. Будь-яка файлова система повинна мати засоби виправлення помилок, що виникають при записі інформації на диск. Система HPFS для цього використовує механізм аварійного заміщення (hotfix).
Якщо файлова система HPFS зіштовхується з проблемою в процесі запису даних на диск, вона виводить на екран відповідне повідомлення про помилку. Потім HPFS зберігає інформацію, що повинна була бути записана в дефектний сектор, в одному з запасних секторів, заздалегідь зарезервованих на цей випадок. Список вільних запасних блоків зберігається в резервному блоці HPFS. При виявленні помилки під час запису даних в нормальний блок HPFS вибирає один з вільних запасних блоків і зберігає ці дані в ньому. Потім файлова система обновляє карту аварійного заміщення в резервному блоці. Ця карта являє собою просто пари подвійних слів, кожне з яких є 32-бітним номером сектора. Перший номер вказує на дефектний сектор, а другий — на той сектор серед наявних запасних секторів, що був обраний для його заміни. Після заміни дефектного сектора запасним карта аварійного заміщення записується на диск, і на екрані з'являється спливаюче вікно, що інформує користувача про помилку запису, що відбулася, на диск. Щораз, коли система виконує запис чи читання сектора диска, він переглядає карту аварійного заміщення і підмінює всі номери дефектних секторів номерами запасних секторів з відповідними даними. Варто помітити, що це перетворення номерів істотно не впливає на продуктивність системи, тому що воно виконується тільки при фізичному звертанні до диска, але не при читанні даних з дискового кешу. Очищення карти аварійного заміщення автоматично виконується програмою CHKDSK при перевірці диска HPFS. Для кожного заміщеного блоку (сектора) програма CHKDSK виділяє новий сектор у найбільш придатному для файлу (якому належать дані) місці жорсткого диска. Потім програма переміщає дані з запасного блоку в цей сектор і обновляє інформацію про положення файлу, що може зажадати нового балансування дерева блоків розміщення. Після цього CHKDSK вносить ушкоджений сектор у список дефектних блоків, що зберігається в додатковому блоці HPFS, і повертає звільнений сектор у список вільних запасних секторів резервного блоку. Потім видаляє запис з карти аварійного заміщення і записує відредаговану карту на диск.
Всі основні файлові об'єкти в HPFS, у тому числі файлові вузли, блоки розміщення і блоки каталогів, мають унікальні 32-бітні ідентифікатори і покажчики на свої батьківські і дочірні блоки. Файлові вузли, крім того, містять скорочене ім'я свого файлу чи каталогу. Надмірність і взаємозв'язок файлових структур HPFS дозволяють програмі CHKDSK цілком відновлювати файлову структуру диска, послідовно аналізуючи усі файлові вузли, блоки розміщення і блоки каталогів. Керуючись зібраною інформацією, CHKDSK реконструює файли і каталоги, а потім заново створює бітові карти вільних секторів диска. Запуск програми CHKDSK варто здійснювати з відповідними ключами. Так, наприклад, один з варіантів роботи цієї програми дозволяє знайти і відновити вилучені файли.
HPFS відноситься до так званих монтуючим файловим системам. Це означає, що вона не вбудована в операційну систему, а додається до неї при необхідності. Файлова система HPFS встановлюється оператором IFS у файлі CONFIG.SYS. Цей оператор завжди поміщається в першому рядку даного конфігураційного файлу. У прикладі, що далі приводиться, оператор IFS встановлює файлову систему HPFS з кешем у 2 Мбайт, довжиною запису кешу в 8 Кбайт і автоматичною процедурою перевірки дисків С и D:
IFS=E: \OS2\HPFS.IFS /CACHE :2048 /CRECL:4/AUTOCHECK:CD
Для запуску програми керування процесом кешування варто прописати у файлі CONFIG.SYS ще один рядок:
RUN=Е:\OS2\CACHE.EXE /Lazy:0n /BufferIdle:2000 /DiskIdle:4000 /MaxAge:8000 /DirtyMax:256 /ReadAhead:On
У цьому рядку включається режим відкладеного («ледачого») запису, установлюються параметри роботи цього режиму, а також включається режим попереднього читання даних, що в цілому дозволяє істотно скоротити кількість звертань до диска і відчутно підвищити швидкодію файлової системи. Так, ключ Lazy з параметром On включає «ледачий запис», а з параметром Off — виключає. Ключ BufferIdle визначає час у мілісекундах, протягом якого буфер кешу повинний залишатися в неактивному стані, щоб стало можливим здійснити запис даних з кешу на диск. За замовчуванням (тобто якщо не прописувати даний ключ явно) цей час дорівнює 500 мс. Ключ DiskIdle задає час (у мілісекундах), протягом якого диск повинний залишатися в неактивному стані, щоб стало можливим здійснити запис даних з кешу на диск. За замовчуванням цей час дорівнює 1 с. Цей параметр дозволяє уникнути запису з кешу на диск під час виконання інших операцій з диском.
Ключ MaxAge задає час (теж у мілісекундах), після закінчення якого часто охоронювані в кеші дані нарешті позначаються як «застарілі» і при переповненні кешу можуть бути заміщені новими. За замовчуванням цей час дорівнює 5 с. Інші подробиці установки параметрів і можливі значення ключів є в HELP-файлах, установлюваних разом з операційною системою OS/2 Warp.
Нарешті, варто сказати і ще про одну систему керування файлами — мова йде про реалізацію HPFS для роботи на серверах, що функціонують під керуванням OS/2. Це система керування файлами, що одержала назву HPFS386.IFS. Її принципова відмінність від системи HPFS.IFS полягає в тім, що HPFS386.IFS дозволяє (за допомогою більш повного використання технології розширених атрибутів) організувати обмеження на доступ до файлів і каталогів за допомогою відповідних списків доступу — ACL (access control list). Ця технологія, як відомо, використовується у файловій системі NTFS. Крім цього, у системі HPFS386.IFS на відміну від HPFS.IFS немає обмежень на обсяг пам'яті, виділюваної для кешування файлових записів. Іншими словами, при наявності достатнього обсягу оперативної пам'яті обсяг файлового кешу може бути в кілька десятків мегабайт, у той час як для звичайної HPFS.IFS цей об‘єм не може перевищувати 2 Мбайт, що по сьогоднішніх мірках безумовно мало. Нарешті, при установці режимів роботи файлового кешу HPFS386.IFS є можливість явно вказати алгоритм кешування. Найбільш ефективним алгоритмом можна вважати так званий «елеваторний», коли при записі даних з кешу на диск вони попередньо упорядковуються таким чином, щоб мінімізувати час, що відводиться на позиціювання голівок читання/запису. Голівки читання/запису при цьому переміщаються від зовнішніх циліндрів до внутрішнього і по ходу свого руху здійснюють запис і читання даних у відповідності зі спеціальним образом впорядковуючим списком запитів на дискові операції.
Приведемо приклад запису рядків у конфігураційному файлі CONFIG.SYS, що встановлюють систему HPFS386.IFS і визначають параметри роботи підсистеми кешування:
IFS=E: \IBM386FS\HPFS386.IFS /AUTOCHECK:EGH
RUN=E: \IBM386FS\CACHE386.EXE /Lauzy:0n /BufferIdle:4000 /MaxAge:20000
Ці записи варто розуміти в такий спосіб. При запуску операційної системи у випадку виявлення прапора, що означає, що не усі файли були закриті в процесі попередньої роботи, система керування файлами HPFS386.IFS спочатку запустить програму перевірки цілісності файлової системи для томів Е:, G: і Н:. Для кешування файлів при роботі цієї системи керування файлами встановлюється режим відкладеного запису з часом життя буферів до 20 с. Інші параметри, зокрема алгоритм обслуговування запитів, встановлюються у файлі HPFS386.INI, що у даному випадку розташовується в директорії E:\IBM386FS.
Опишемо коротко деякі найбільш цікаві параметри, що керують роботою кешу в цій системі керування файлами. Насамперед відзначимо, що файл HPFS386.INI розбитий на кілька секцій. В даний момент розглянемо секцію [ULTIMEDIA]:
[ULTIMEOIA]
QUEUESORT={FIFO|ELEVATOR|DEFAULT|CURRENT}
QUEUEMETHOD={PRIORITY|NOPRIORITY|DEFAULT|CURRENT}
QUEUEDEPTH-{1...255|DEFAULT|CURRENT}
Параметр QUEUESORT задає спосіб ведення черги запитів до диска. Він може приймати значення FIFO, ELEVATOR, DEFAULT і CURRENT. Якщо задане значення FIFO, то кожен новий запит просто додається в кінець черги, тобто запити виконуються в тім порядку, у якому вони надходять у систему. Однак можна впорядкувати деяку кількість запитів по зростанню номерів доріжок. Якщо задане значення ELEVATOR, то включається режим підтримки впорядкованої черги запитів. При цьому запити починають оброблятися по алгоритму ELEVATOR (він же C-SCAN чи «режим плаваючої голівки»). Нагадаємо, цей алгоритм має на увазі, що голівка читання/запису сканує диск в обраному напрямку (наприклад, у напрямку зростання номерів доріжок), зупиняючись для виконання запитів, що знаходяться на шляху проходження. Коли вона доходить до останнього запиту, голівка читання/запису переноситься на початкову доріжку і процесобслуговування запитів продовжується. Якщо для параметра QUEUESORT задане значення DEFAULT, то вибирається алгоритм за замовчуванням. Зараз це ELEVATOR. Якщо задане значення CURRENT, то залишається в силі; той алгоритм, що був обраний DASD Manager при ініціалізації.
Параметр QUEUEMETHOD визначає, чи повинні враховуватися пріоритети запитів при побудові черги. Він може приймати значення PRIORITY, NOPRIORITY, DEFAULT і CURRENT. Якщо задане значення NOPRIORITY, то всі запити включаються в загальну чергу, а їхні пріоритети ігноруються. Якщо додане значення PRIORITY, то модуль DASD Manager буде підтримувати кілька черг запитів, по одній на кожен пріоритет. Коли DASD Manager передасть запити на виконаннядрайверу диска, він спочатку вибирає запити із самої пріоритетної черги, потім з менш пріоритетної і т.д. Пріоритети призначає HPFS386, а розподілені вони в такий спосіб.
High:
1. Shutdown чи екстрений запис через збій живлення.
2. Сторінковий обмін.
3. Звичайні запити від foreground сесії.
4. Звичайні запити від background сесії. (Пріоритети 3 і 4 рівні, якщо у файлі CONFIG.SYS заданий параметр RIORITY_DISK_IO=NO.)
5. Read-ahead і низькопріоритетні запити сторінкового обміну (сторінкова предвибірка).
6. Lazy-Write та інші запити, що не вимагають негайної реакції.
Low:
7. Предвибірка.
Якщо для параметра QUEUEMETHOD задане значення DEFAULT, то вибирається метод за замовчуванням. Зараз це PRIORITY. Якщо задане значення CURRENT, то залишається в силі той метод, що був обраний DASD Manager при ініціалізації.
Параметр QUEUEDEPTH задає глибину перегляду черги при вибірці запитів. Він може приймати значення з діапазону (1...255), а також DEFAULT і CURRENT. Якщо в якості значення параметра QUEUEDEPTH задане число, то воно визначає кількість запитів, що повинні знаходитися в черзі дискового адаптера одночасно. Наприклад, для SCSI-адаптерів має сенс підтримувати таку довжину черги, при якій вони зможуть завантажити всі запити у свої апаратні структури (tagged queue чи mailbox). Якщо черга запитів до адаптера буде занадто короткою, то апаратура буде працювати з неповним завантаженням, а якщо вона буде занадто довгою — драйвер SCSI-адаптера буде перевантажений «зайвими» запитами. Тому розумним значенням для QUEUEDEPTH буде число, що небагато перевищує довжину апаратної черги команд адаптера. Якщо для параметра QUEUEDEPTH задане значення DEFAULT, то глибина перегляду черги визначається автоматично на підставі значення, що рекомендоване драйвером дискового адаптера. Якщо задане значення CURRENT, то глибина перегляду черги не змінюється. У поточній реалізації CURRENT еквівалентно DEFAULT.
Отже, поточні замовчування для HPFS386 мають вигляд:
QUEUESORT=FIFO
QUEUEMETHOD=DEFAULT
QUEUEDEPTH=2
А поточні замовчування для DASD Manager такі:
QUEUESORT=ELEVATOR
QUEUEMETHOD=PRIORITY
QUEUEDEPTH=<залежить від адаптера диска>
Замовчування DASD Manager можна змінювати за допомогою параметра /QF:
BASEDEV=OS2DASD.DMD /QF:{1|2|3}
де 1 - QUEUESORT = FIFO; 2 - QUEUEMETHOD = NOPRIORITY; 3 - QUEUESORT = FIFO і
QUEUEMETHOD = NOPRIORITY.
Нарешті, додамо ще кілька слів про встановлювані файлові системи (installable file systems — IPS), що представляють собою спеціальні «драйвери» для доступу до розділів, відформатованим під іншу файлову систему . Це дуже зручний і могутній механізм додавання в ОС нових файлових систем і заміни однієї системи керування файлами на іншу. Сьогодні, наприклад, для OS/2 уже реально існують IFS-модулі для файлової системи VFAT (FAT з підтримкою довгих імен), FAT32, Ext2FS (файлова система Linux), NTFS (правда, поки тільки для читання). Для роботи з даними на CD-ROM мається CDFS.IFS. Є і FTP.IFS, що дозволяє монтувати ftp-архіви як локальні диски. Механізм встановлюваних файлових систем був перенесений і в систему Windows NT.
Дата добавления: 2016-07-27; просмотров: 2274;
Поиск по сайту
Узнать еще
- Arthropoda. Клещи. Систематика. Морфология. Медицинское значение.
- Arthropoda. Паукообразные. Систематика. Географическое распространение. Морфология. Скорпионы. Пауки. Медицинское значение.
- Arthropoda..Систематика.Насекомые.Морфология.Классификация.Медицинское значение.
- Arthropoda.Систематика.Блохи.Виды блох.Географическое распространение.Морфология,развитие,патогенное действие.Медицинское и эпидемиологическое значение.Меры борьбы.
- Arthropoda.Систематика.Мошки,мокрецы,слепни,оводы.Географическое распространение.Морфология,развитие,патогенное действие.Медицинское значение,меры борьбы.
- Arthropoda.Систематика.Тараканы и мухи.Географическое распространение.Основные представители.Морфология,развитие,патогенное действие.Медицинское знаение.Меры борьбы.
- Cимпатическая нервная система. Центральный и периферический отдел симпатической нервной системы.
- D) Система класифікації за підтримкою багато гілкового виконання програми.

Публикации по технике и механике

Публикации по биологии

Публикации по информатике

Публикации по строительству

Публикации по физике

Публикации по химии

Публикации по электронике

Публикации по искусству

Публикации по истории
