Морфологическая информация, этапы морфологического разбора текста
Цель МА — определить принадлежность некоторой словоформы к парадигме определенной лексемы и грамматические признаки для этой словоформы – морфологическую информацию (МИ) для использования ее на последующих этапах обработки ЕЯ текста.
Так для существительных этими признаками будут: род, число, падеж и склонение, для прилагательных: род, число и падеж; для глаголов - время, лицо, число, спряжение, вид; для местоимений – число и лицо. Классификация морфологических признаков слов русского языка изображена на рисунке 5.1.
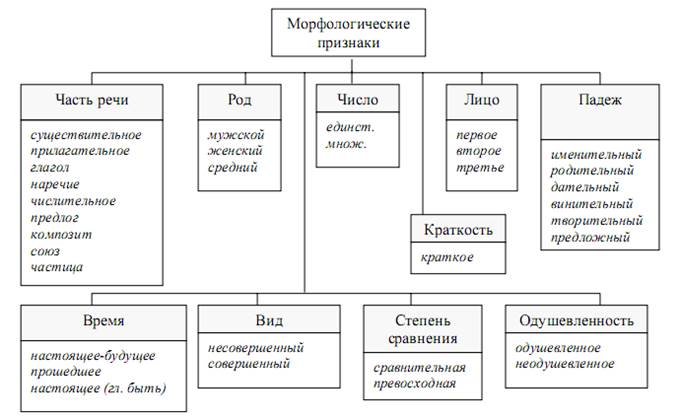
Рис.5.1. Морфологические признаки слов русского языка
Для русского языка, как и для большинства синтетических языков, задача лексико-грамматического разбора решается довольно просто и почти стопроцентной точностью, благодаря их развитой морфологии. В аналитических языках, например английском, где широко представлена лексическая многозначность, простой алгоритм, сопоставляющий каждому слову в тексте наиболее вероятный для данного слова морфологический класс, дает лишь около 90% точности.
Для синтетических языков морфологический разбор текста включает:
1. Выделение внутри предложений отдельных словоформ.
2. Определение всех вариантов комбинаций основ и аффиксов для каждой словоформы и, соответственно, вариантов грамматических форм.
3. Устранение грамматической неоднозначности на основе комбинаторного словаря, содержащего все контексты употребления слов.
Для увеличения точности разбора используются два типа алгоритмов: вероятностно-статистические и основанные на продукционных правилах.
Алгоритмы, основанные на продукционных правилах, используют правила, которые строятся автоматически на основе некоторого корпуса текстов или создаются лингвистами.
Вероятностно-статистические алгоритмы используют, в основном, два источника информации.
- Словарь словоформ, в котором каждой словоформе соответствует множество лексико-грамматических классов, которые могут быть у данной словоформы. Для каждого лексико-грамматического класса указывается частота его встречаемости относительно других морфологических классов данной словоформы.
- Информация о встречаемости всех возможных последовательностей морфологических классов попарно, по тройкам, по четверкам и т.д. с относительной частотой такой пары (тройки, четверки и т.д.). Эта информация обрабатывается неким статистическим алгоритмом (например, на основе скрытых цепей Маркова) для нахождения наиболее вероятного лексико-грамматического класса для каждого слова в предложении.
Оба подхода дают примерно одинаковый результат на уровне 96-98 % точности.
Существует несколько классификаций основных видов алгоритмов морфологического анализа. По использованию словарей системы МА можно разделить на словарные (со словарем словоформ или со словарем основ) и бессловарные, а по организации алгоритмов — на методы с декларативной, процедурной и комбинированной ориентацией.
Дата добавления: 2016-07-18; просмотров: 2782;
Поиск по сайту
Узнать еще
- MS Word. Выделение текста. Понятие фрагмента текста. Способы форматирования фрагментов, работа с фрагментами (копирование, удаление, перемещение).
- Story Editor (редактор текста)
- TMemo - ввод и отображение текста
- А- технологические этапы изготовления
- Активизация PDP контекста.
- Акушерство как наука. Этапы развития акушерства.
- Алгоритм и этапы решения задачи
- Алгоритмы и этапы проектирования цифровых устройств

Публикации по технике и механике

Публикации по биологии

Публикации по информатике

Публикации по строительству

Публикации по физике

Публикации по химии

Публикации по электронике

Публикации по искусству

Публикации по истории
