Динамическое распределение
Для преодоления сложностей, связанных с фиксированным распределением, был разработан альтернативный подход, известный как динамическое распределение. Этот подход в настоящее время также вытеснен более сложными и эффективными технологиями управления памятью. В свое время динамическое распределение использовала операционная система IBM для мейнфреймов OS/MVT (многозадачная с переменным количеством задач — Multiprogramming with a Variable number of Tasks).
При динамическом распределении образуется переменное количество разделов переменной длины. При размещении процесса в основной памяти для него выделяется строго необходимое количество памяти, и не более. В качестве примера рассмотрим использование 64 Мбайт основной памяти (рис. 7.4). Изначально вся память пуста, за исключением области, используемой операционной системой (рис. 7.4,а). Первые три процесса загружаются в память, начиная с адреса, которым заканчивается операционная система, и используя ровно столько памяти, сколько требуется данному процессу (рис. 7.4,6-г). После этого в конце основной памяти остается "дыра", слишком малая для размещения четвертого процесса. В некоторый момент все процессы в памяти оказываются неактивными, и операционная система выгружает второй процесс (рис. 7.4.,д), после которого остается достаточно памяти для загрузки нового, четвертого процесса (рис. 7.4,е). Поскольку процесс 4 меньше процесса 2, создается еще одна небольшая "дыра" в памяти. После того как в некоторый момент времени все процессы в памяти оказываются неактивными, но зато готов к работе процесс 2, свободного места в памяти для него не находится, и операционная система вынуждена выгрузить процесс 1, чтобы освободить необходимое место (рис. 7.4,ж) и разместить процесс 2 в основной памяти (рис. 7.4,з).
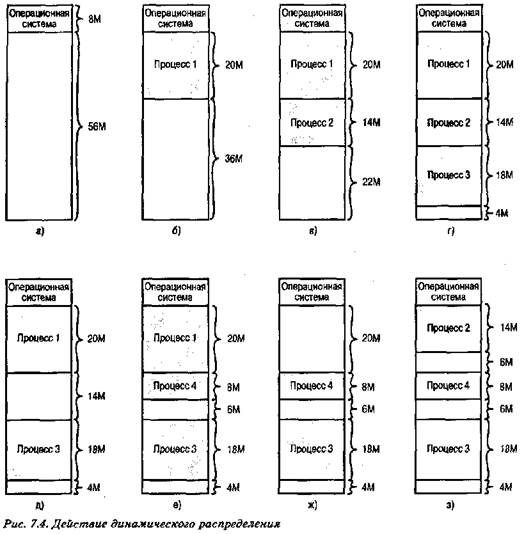
Как показывает данный пример, этот метод хорошо начинает работу, но плохо продолжает — в конечном счете он приводит к наличию множества мелких дыр в памяти. Со временем память становится все более и более фрагментированной, и снижается эффективность ее использования. Это явление называется внешнейфрагментацией (external fragmentation), что отражает тот факт, что сильно фрагментированной становится память, внешняя по отношению ко всем разделам (в отличие от рассмотренной ранее внутренней фрагментации).
Один из методов преодоления этого явления состоит в уплотнении (compaction): время от времени операционная система перемещает процессы в памяти так, чтобы они занимали смежные области памяти; свободная память при этом собирается в один блок. Например, на рис. 7.4,з после уплотнения памяти мы получим блок свободной памяти размером 16 Мбайт, чего может оказаться вполне достаточно для загрузки нового процесса. Сложность применения уплотнения состоит в том, что при этом расходуется дополнительное время; кроме того, уплотнение требует динамического перемещения процессов в памяти, т.е. должна быть обеспечена возможность перемещения программы из одной области основной памяти в другую без потери корректности ее обращений к памяти (см. приложение к данной главе).
Алгоритм размещения
Поскольку уплотнение памяти вызывает дополнительные расходы времени процессора, разработчик операционной системы должен принять разумное решение о том, каким образом размещать процессы в памяти (образно говоря, каким образом затыкать дыры). Когда наступает момент загрузки процесса в основную память и имеется несколько блоков свободной памяти достаточного размера, операционная система должна принять решение о том, какой именно свободный блок использовать.
Можно рассматривать три основных алгоритма — наилучший подходящий, первый подходящий, следующий подходящий. Все они, само собой разумеется, ограничены выбором среди свободных блоков размера, достаточно большого для размещения процесса. Метод наилучшего подходящего выбирает блок, размер которого наиболее близок к требуемому; метод первого подходящего проверяет все свободные блоки с начала памяти и выбирает первый достаточный по размеру для размещения процесса. Метод следующего подходящего работает так же, как и метод первого подходящего, однако начинает проверку с того места, где был выделен блок в последний раз (по достижении конца памяти он продолжает работу с ее начала).
На рис. 7.5,а показан пример конфигурации памяти после ряда размещений и выгрузки процессов из памяти. Последним использованным блоком был блок размером 22 Мбайт, в котором был создан раздел в 14 Мбайт. На рис. 7.5,6 показано различие в технологии наилучшего, первого и следующего подходящего при выполнении запроса на выделение блока размером 16 Мбайт. Метод наилучшего подходящего просматривает все свободные блоки и выбирает наиболее близкий по размеру блок в 18 Мбайт, оставляя фрагмент размером 2 Мбайт. Метод первого подходящего в данной ситуации оставляет фрагмент свободной памяти размером 6 Мбайт, а метод следующего подходящего — 20 Мбайт.
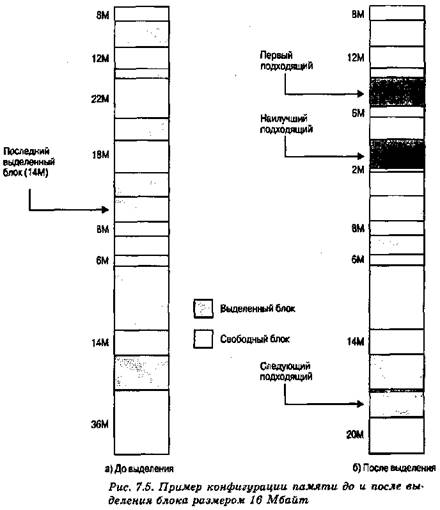
Какой из этих методов окажется наилучшим, будет зависеть от точной последовательности загрузки и выгрузки процессов и их размеров. Однако можно говорить о некоторых обобщенных выводах (см. [BREN89], [SHOR75], [BAYS77]). Обычно алгоритм первого подходящего не только проще, но и быстрее и дает лучшие результаты. Алгоритм следующего подходящего, как правило, дает немного худшие результаты. Это связано с тем, что алгоритм следующего подходящего проявляет склонность к более частому выделению памяти из свободных блоков в конце памяти. В результате самые большие блоки свободной памяти (которые обычно располагаются в конце памяти) быстро разбиваются на меньшие фрагменты и, следовательно, при использовании метода следующего подходящего уплотнение должно выполняться чаще. С другой стороны, алгоритм первого подходящего обычно засоряет начало памяти небольшими свободными блоками, что приводит к увеличению времени поиска подходящего блока в последующем. Метод наилучшего подходящего, вопреки своему названию, оказывается, как правило, наихудшим. Так как он ищет блоки, наиболее близкие по размеру к требуемому, он оставляет после себя множество очень маленьких блоков. В результате, хотя при каждом выделении впустую тратится наименьшее возможное количество памяти, основная память очень быстро засоряется множеством мелких блоков, неспособных удовлетворить ни один запрос (так что при этом алгоритме уплотнение памяти должно выполняться значительно чаще).
Алгоритм замещения
В многозадачной системе с использованием динамического распределения наступает момент, когда все процессы в основной памяти находятся в заблокированном состоянии, а памяти для дополнительного процесса недостаточно даже после уплотнения. Чтобы избежать потерь процессорного времени на ожидание деблокирования активного процесса, операционная система может выгрузить один из процессов из основной памяти, и, таким образом, освободить место для нового процесса, или процесса в состоянии готовности. Задача операционной системы — определить, какой именно процесс должен быть выгружен из памяти. Поскольку тема алгоритма замещения будет детально рассматриваться в связи с различными схемами виртуальной памяти, пока что мы отложим обсуждение этого вопроса.
Система двойников
Как фиксированное, так и динамическое распределение памяти имеют свои недостатки. Фиксированное распределение ограничивает количество активных процессов и неэффективно использует память при несоответствии между размерами разделов и процессов. Динамическое распределение реализуется более сложно и включает накладные расходы по уплотнению памяти. Интересным компромиссом в этом плане является система двойников ([KNUT97], [РЕТЕ77]).
В системе двойников память распределяется блоками размером 2k, L<K<U,
где
2L — минимальный размер выделяемого блока памяти;
2U— наибольший распределяемый блок; вообще говоря, 2Uпредставляет собой размер всей доступной для распределения памяти.
Вначале все доступное для распределения пространство рассматривается как единый блок размера 2U. При запросе размером s, таким, что 2U-1 < s <=2U , выделяется весь блок. В противном случае блок разделяется на два эквивалентных двойника с размерами 2U-1, Если 2U-2 < s < 2U, то по запросу выделяется один из двух двойников; в противном случае один из двойников вновь делится пополам. Этот процесс продолжается до тех пор, пока не будет сгенерирован наименьший блок, размер которого не меньше s. Система двойников постоянно ведет список "дыр" (доступных блоков) для каждого размера 2i. Дыра может быть удалена из списка (i+1) разделением ее пополам и внесением двух новых дыр размера 2i в список i. Когда пара двойников в списке i оказывается освобожденной, они удаляются из списка и объединяются в единый блок в списке (i+1). Ниже приведен рекурсивный алгоритм ([LIST93]) для удовлетворения запроса размера 2i-1<k<=2i, в котором осуществляется поиск дыры размером 2i.
void get_hole(int i)
{
if (i == (U+1)
<Ошибка >;
if (< Список i пуст >)
{
get_hole(i+l);
< Разделить дыру на двойники >;
< Поместить двойники в список i >;
}
< Взятьпервую дыру из списка i >;
}
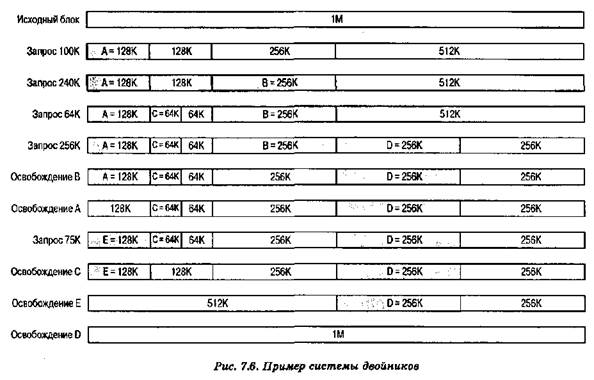
На рис. 7.6 приведен пример использования блока с начальным размером 1 Мбайт. Первый запрос А — на 100 Кбайт (для него требуется блок размером 128 Кбайт). Для этого начальный блок делится на два двойника по 512 Кбайт. Первый из них делится на двойники размером 256 Кбайт, и, в свою очередь, первый из получившихся при этом разделении двойников также делится пополам. Один из получившихся двойников размером 128 Кбайт выделяется запросу А. Следующий запрос В требует 256 Кбайт. Такой блок имеется в наличии и выделяется. Процесс продолжается с разделением и слиянием двойников при необходимости. Обратите внимание, что после освобождения блока Е происходит слияние двойников по 128 Кбайт в один блок размером 256 Кбайт, который, в свою очередь, тут же сливается со своим двойником.
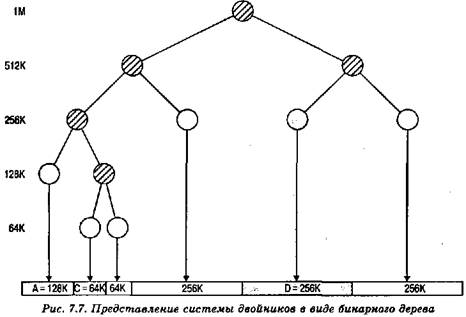
На рис. 7.7 показано представление системы двойников в виде бинарного дерева, непосредственно после освобождения блока В. Листья представляют текущее распределение памяти. Если два двойника являются листьями, то по крайней мере один из них занят; в противном случае они должны слиться в блок большего размера.
Система двойников представляет собой разумный компромисс для преодоления недостатков схем фиксированного и динамического распределения, но в современных операционных системах ее превосходит виртуальная память, основанная на страничной организации и сегментации. Однако система двойников нашла применение в параллельных системах как эффективное средство распределения и освобождения параллельных программ (см., например, [JOHN92]). Модифицированная версия системы двойников используется для распределения памяти ядром UNIX (подробнее об этом вы узнаете в главе 8, "Виртуальная память").
Перемещение
Перед тем как мы рассмотрим способы, с помощью которых можно избежать недостатков распределения, следует до конца разобраться в вопросах, связанных с размещением процессов в памяти. При использовании фиксированной схемы распределения, показанной на рис. 7.3,а, можно ожидать, что процесс всегда будет назначаться одному и тому же разделу памяти. Это означает, что какой бы раздел ни был выбран для нового процесса, для размещения этого процесса после выгрузки и последующей загрузки в память всегда будет использоваться именно этот раздел. В данном случае можно использовать простейший загрузчик, описанный в приложении к данной главе: при загрузке процесса все относительные ссылки в коде замещаются абсолютными адресами памяти, определенными на основе базового адреса загруженного процесса.
Если размеры разделов равны (рис. 7.2) и существует единая очередь процессов для разделов разного размера (рис. 7.3,6), процесс по ходу работы может занимать разные разделы. При первом создании образа процесса он загружается в некоторый раздел памяти; позже, после того как он был выгружен из памяти и вновь загружен, процесс может оказаться в другом разделе (не в том, в котором он размещался в последний раз). Та же ситуация возможна и при динамическом распределении. Так, на рис. 7.4,в и з процесс 2 занимает при размещении в памяти различные места. Кроме того, при выполнении уплотнения процессы также перемещаются в основной памяти. Таким образом, расположение команд и данных, к которым обращается процесс, не является фиксированным и изменяется всякий раз при выгрузке и загрузке (или перемещении) процесса. Для решения этой проблемы следует различать типы адресов. Логический адрес представляет собой ссылку на ячейку памяти, не зависящую от текущего расположения данных в памяти; перед тем как получить доступ к этой ячейке памяти, необходимо транслировать логический адрес в физический. Относительный адрес представляет собой частный случай логического адреса, когда адрес определяется положением относительно некоторой известной точки (обычно — начала программы). Физический адрес (известный также как абсолютный) представляет собой действительное расположение интересующей нас ячейки основной памяти.
Если программа использует относительные адреса, это означает, что все ссылки на память в загружаемом процессе даны относительно начала этой программы. Таким образом, для корректной работы программы требуется аппаратный механизм, который бы транслировал относительные адреса в физические в процессе выполнения команды, которая обращается к памяти.
На рис. 7.8 показан обычно используемый способ трансляции адреса. Когда процесс переходит в состояние выполнения, в специальный регистр процессора, иногда называемый базовым, загружается начальный адрес процесса в основной памяти. Кроме того, используется "граничный" (bounds) регистр, в котором содержится адрес последней ячейки памяти программы. Эти значения заносятся в регистры при загрузке программы в основную память. При выполнении процесса встречающиеся в командах относительные адреса обрабатываются процессором в два этапа. Сначала к относительному адресу прибавляется значение базового регистра для получения абсолютного адреса. Затем полученный абсолютный адрес сравнивается со значением в граничном регистре. Если полученный абсолютный адрес принадлежит данному процессу, команда может быть выполнена; в противном случае генерируется соответствующее данной ошибке прерывание операционной системы.
Схема, представленная на рис. 7.8, обеспечивает возможность выгрузки и загрузки программ в основную память в процессе их выполнения; кроме того, образ каждого процесса ограничен адресами, содержащимися в базовом и граничном регистрах, и защищен от нежелательного доступа со стороны других процессов.
Дата добавления: 2016-06-05; просмотров: 1836;
Поиск по сайту
Узнать еще
- F-распределение Фишера
- I.1.7 СТАТИСТИЧЕСКОЕ РАСПРЕДЕЛЕНИЕ
- II. РАСПРЕДЕЛЕНИЕ ЛЕКАРСТВЕННЫХ СРЕДСТВ В ОРГАНИЗМЕ. БИОЛОГИЧЕСКИЕ БАРЬЕРЫ. ДЕПОНИРОВАНИЕ
- А) распределение ЗС ГО между подразделениями предприятия и их привязка к незаваливаемым оринетирам.
- Анализ факторов, влияющих на распределение доходов населения
- Аэродинамическое качество (L/Dratio).
- Аэродинамическое качество крыла
- Аэродинамическое качество крыла

Публикации по технике и механике

Публикации по биологии

Публикации по информатике

Публикации по строительству

Публикации по физике

Публикации по химии

Публикации по электронике

Публикации по искусству

Публикации по истории
